Table of Contents
With an enormous amount of data stored in databases and data warehouses, it is increasingly important to develop powerful tools for analysis of such data and mining interesting knowledge from it. Data mining is a process of inferring knowledge from such huge data. Data Mining has three major components Clustering or Classification, Association Rules and Sequence Analysis.
By simple definition, in classification/clustering we analyze a set of data and generate a set of grouping rules which can be used to classify future data. For example, one may classify diseases and provide the symptoms which describe each class or subclass. This has much in common with traditional work in statistics and machine learning. However, there are important new issues which arise because of the sheer size of the data. One of the important problem in data mining is the Classification-rule learning which involves finding rules that partition given data into predefined classes. In the data mining domain where millions of records and a large number of attributes are involved, the execution time of existing algorithms can become prohibitive, particularly in interactive applications. This is discussed in detail in Chapter 2.
An association rule is a rule which implies certain association relationships among a set of objects in a database. In this process we discover a set of association rules at multiple levels of abstraction from the relevant set(s) of data in a database. For example, one may discover a set of symptoms often occurring together with certain kinds of diseases and further study the reasons behind them. Since finding interesting association rules in databases may disclose some useful patterns for decision support, selective marketing, financial forecast, medical diagnosis, and many other applications, it has attracted a lot of attention in recent data mining research . Mining association rules may require iterative scanning of large transaction or relational databases which is quite costly in processing. Therefore, efficient mining of association rules in transaction and/or relational databases has been studied substantially. This is discussed in detail in Chapter 3.
In sequential Analysis, we seek to discover patterns that occur in sequence. This deals with data that appear in separate transactions (as opposed to data that appear in the same transaction in the case of association).For e.g. : If a shopper buys item A in the first week of the month, then s/he buys item B in the second week etc. This is discussed in detail in Chapter 4.
There are many algorithms proposed that try to address the above aspects of data mining. Compiling a list of all algorithms suggested/used for these problems is an arduous task . I have thus limited the focus of this report to list only some of the algorithms that have had better success than the others. I have included a list of URLs in Appendix A which can be referred to for more information on data mining algorithms.
In Data classification one develops a description or model for each class in a database, based on the features present in a set of class-labeled training data. There have been many data classification methods studied, including decision-tree methods, such as C4.5, statistical methods, neural networks, rough sets, database-oriented methods etc.
In this paper, I have discussed in detail some of the machine-learning algorithms that have been successfully applied in the initial stages of this field. The other methods listed above are just being applied to data mining and have not been very successful. This section briefly describes these other methods. Appendix A lists the URLs which can be referred to for more information on these various methods.
Many existing algorithms suggest abstracting the test data before
classifying
it into various classes. There are several alternatives for doing abstraction
before classification: A data set can be generalized to either a minimally
generalized abstraction level, an intermediate abstraction level, or a
rather high abstraction level. Too low an abstraction level may result
in scattered classes, bushy classification trees, and difficulty at concise
semantic interpretation; whereas too high a level may result in the loss
of classification accuracy. The generalization-based multi-level
classification
process has been implemented in the DB-Miner system.[4]
Classification-rule learning involves finding rules or decision trees that partition given data into predefined classes. For any realistic problem domain of the classification-rule learning, the set of possible decision trees is too large to be searched exhaustively. In fact, the computational complexity of finding an optimal classification decision tree is NP hard.
Most of the existing induction-based algorithms use Hunt's method as the basic algorithm.[2] Here is a recursive description of Hunt's method for constructing a decision tree from a set T of training cases with classes denoted {C1, C2, ,Ck }.
Case 1 T contains one or more cases, all belonging to a single
class Cj : The decision tree for T is a leaf identifying class
Cj .
Case 2 T contains no cases: The decision tree for T is a leaf,
but the class to be associated with the leaf must be determined from
information
other than T.
Case 3 T contains cases that belong to a mixture of classes:
A test is chosen, based on a single attribute, that has one or more mutually
exclusive outcomes {O1, O2 , .. ,On }.
T is partitioned into subsets T1, T2,
,Tn
, where Ti contains all the cases in T that have outcome
Oi
of the chosen test. The decision tree for T consists of a decision node
identifying the test, and one branch for each possible outcome. The same
tree building machinery is applied recursively to each subset of training
cases.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| Attribute Value |
|
|
| Play | Don't Play | |
| sunny | 2 | 3 |
| overcast | 4 | 0 |
| rain | 3 | 2 |
| Attribute Value | Binary Test |
|
|
| Play | Don't Play | ||
| 65 | 1 | 0 | |
| > | 8 | 5 | |
| 70 | 3 | 1 | |
| > | 6 | 4 | |
| 75 | 4 | 1 | |
| > | 5 | 4 | |
| 78 | 5 | 1 | |
| > | 4 | 4 | |
| 80 | 7 | 2 | |
| > | 2 | 3 | |
| 85 | 7 | 3 | |
| > | 2 | 2 | |
| 90 | 8 | 4 | |
| > | 1 | 1 | |
| 95 | 8 | 5 | |
| > | 1 | 0 | |
| 96 | 9 | 5 | |
| > | 0 | 0 | |
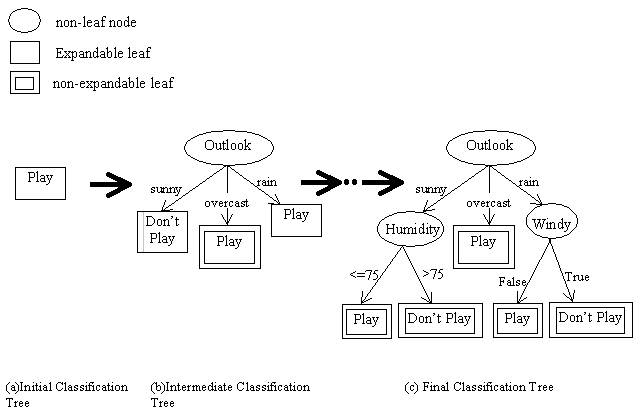
Table 2.1 shows a training data set with four data attributes and two
classes. Figure 2.1 shows how the Hunt's method works with the training
data set. In the case 3 of the Hunt's method, a test based on a single
attribute is chosen for expanding the current node. The choice of an
attribute
is normally based on the entropy gains of the attributes. The entropy of
an attribute is calculated from class distribution information. For a
discrete
attribute, class distribution information of each value of the attribute
is required. Table 2.2 shows the class distribution information of data
attribute Outlook. For a continuous attribute, binary test involving all
the distinct values of the attribute is considered. Table 2.3 shows the
class distribution information of data attribute Humidity. Once the class
distribution information of all the attributes are gathered, the entropy
is calculated based on either information theory or Gini Index. One attribute
with the most entropy gain is selected as a test for the node expansion.
While SLIQ handles disk-resident data that are too large to fit in memory,
it still requires some information to stay memory-resident which grows
in direct proportion to the number of input records, putting a hard-limit
on the size of training data. The Quest team has recently designed a new
decision-tree-based classification algorithm, called SPRINT (Scalable
PaRallelizable INduction of decision Trees)
that for the removes all of the memory restrictions.
Nearest-neighbor The classical nearest-neighbor with options for weight setting, normalizations, and editing (Dasarathy 1990, Aha 1992, Wettschereck 1994).
Naive-Bayes A simple induction algorithm that assumes a conditional independence model of attributes given the label (Domingos & Pazzani 1996, Langley, Iba & Thompson 1992, Duda & Hart 1973, Good 1965).
OODG Oblivous read-Once Decision Graph induction algorithm described in Kohavi (1995c).
Lazy decision trees An algorithm for building the ``best'' decision tree for every test instance described in Friedman, Kohavi & Yun (1996).
Decision Table A simple lookup table. A simple algorithm that is useful with feature subset selection
Most of the existing algorithms, use local heuristics to handle the computational complexity. The computational complexity of these algorithms ranges from O(AN logN) to O(AN(logN)2 ) with N training data items and A attributes. These algorithms are fast enough for application domains where N is relatively small. However, in the data mining domain where millions of records and a large number of attributes are involved, the execution time of these algorithms can become prohibitive, particularly in interactive applications. Parallel algorithms have been suggested by many groups developing data mining algorithms. We discuss below two approaches that have been used.[2]
Initially N training data items are randomly distributed to P processors such that each processors has N=P data items. At this point, all the processors cooperate to expand the root node of a decision tree. For this, processors need to decide on an attribute to use to generate child nodes of the root. This can be done in three steps. In the first step, every processor collects the class distribution information of the local data. In the second step, the processors exchange the local class distribution information using global reduction. Finally, each processor can simultaneously compute entropy gains of the attributes and find the best attribute for splitting the root node.There are two approaches for further progress. In Synchronous Tree Construction Approach, the entire set of processors synchronously expand one node of the decision tree at a time. In partitioned Tree Construction Approach, each new generated node is expanded by a subset of processors that helped the expansion of the parent node. These are discussed below .
In this approach, all processors construct a decision tree synchronously by sending andreceiving class distribution information of local data.
Major steps for the approach are shown below:
Load imbalance can be reduced if all the nodes on the frontier are expanded simultaneously, i.e. one pass of all the data at each processor is used to compute the class distribution information for all nodes on the frontier. Note that this improvement also reduces the number of times communications are done and reduces the message start-up overhead, but it does not reduce the overall volume of communications. Now the only source of load imbalance is when some leaf nodes become terminal nodes. This load imbalance can be further minimized if the training data set is distributed randomly.
In this approach, each leaf node n of the frontier of the decision tree is handled by a distinct subset of processors P(n). Once the node n is expanded into child nodes, n1, n2, ,nk, the processor group P(n) is also partitioned into k parts, P1, P2, ,Pk , such that Pi handle node ni . All the data items are shuffled such that the processors in group Pi have data items that belong to the leaf ni only. Major steps for the approach is shown below:
An association rule mining algorithm, Apriori has been developed for rule mining in large transaction databases by IBM's Quest project team[3] . A itemset is a non-empty set of items.
They have decomposed the problem of mining association rules into two parts
It makes multiple passes over the database. In the first pass, the algorithm simply counts item occurrences to determine the frequent 1-itemsets (itemsets with 1 item). A subsequent pass, say pass k, consists of two phases. First, the frequent itemsets Lk-1 (the set of all frequent (k-1)-itemsets) found in the (k-1)th pass are used to generate the candidate itemsets Ck, using the apriori-gen() function. This function first joins Lk-1 with Lk-1, the joining condition being that the lexicographically ordered first k-2 items are the same. Next, it deletes all those itemsets from the join result that have some (k-1)-subset that is not in Lk-1 yielding Ck.
The algorithm now scans the database. For each transaction, it determines
which of the candidates in Ck are contained in the transaction
using a hash-tree data structure and increments the count of those
candidates.
At the end of the pass, Ck is examined to determine which of
the candidates are frequent, yielding Lk . The algorithm
terminates
when Lk becomes empty.
Distributed/Parallel
Algorithms
Databases or data warehouses may store a huge amount of data to be mined. Mining association rules in such databases may require substantial processing power . A possible solution to this problem can be a distributed system.[5] . Moreover, many large databases are distributed in nature which may make it more feasible to use distributed algorithms.
Major cost of mining association rules is the computation of the set of large itemsets in the database. Distributed computing of large itemsets encounters some new problems. One may compute locally large itemsets easily, but a locally large itemset may not be globally large. Since it is very expensive to broadcast the whole data set to other sites, one option is to broadcast all the counts of all the itemsets, no matter locally large or small, to other sites. However, a database may contain enormous combinations of itemsets, and it will involve passing a huge number of messages.
A distributed data mining algorithm FDM (Fast Distributed Mining of association rules) has been proposed by [5], which has the following distinct features.
The input data is a set of sequences, called data-sequences. Each data sequence is a ordered list of transactions(or itemsets), where each transaction is a sets of items (literals). Typically there is a transaction-time associated with each transaction. A sequential pattern also consists of a list of sets of items. The problem is to find all sequential patterns with a user-specified minimum support, where the support of a sequential pattern is the percentage of data sequences that contain the pattern.
An example of such a pattern is that customers typically rent ``Star
Wars'', then ``Empire Strikes Back'', and then ``Return of the Jedi''.
Note that these rentals need not be consecutive. Customers who rent some
other videos in between also support this sequential pattern. Elements
of a sequential pattern need not be simple items. ``Fitted Sheet and flat
sheet and pillow cases'', followed by ``comforter'', followed by ``drapes
and ruffles'' is an example of a sequential pattern in which the elements
are sets of items. This problem was initially motivated by applications
in the retailing industry, including attached mailing, add-on sales, and
customer satisfaction. But the results apply to many scientific and business
domains. For instance, in the medical domain, a data-sequence may correspond
to the symptoms or diseases of a patient, with a transaction corresponding
to the symptoms exhibited or diseases diagnosed during a visit to the doctor.
The patterns discovered using this data could be used in disease research
to help identify symptoms/diseases that precede certain diseases.
Algorithms for Finding Sequential Patterns
Various groups working in this field have suggested algorithms for mining sequential patterns. Listed below are two algorithms proposed by IBM's Quest data team.[6]
Terminology : The length of a sequence is the number of itemsets in the sequence. A sequence of length k is called a k-sequence. The sequence formed by the concatenation of two sequences x and y is denoted as x.y. The support for an itemset i is defined as the fraction of customers who bought the items in i in a single transaction. Thus the itemset i and the 1-sequence i have the same support. An itemset with minimum support is called a large itemset or litemset. Note that each itemset in a large sequence must have minimum support. Hence, any large sequence must be a list of litemsets. In the algorithms, Lk denotes the set of all large k-sequences, and Ck the set of candidate k-sequences.
The problem of mining sequential patterns can be split into the following phases:There are two families of algorithms- count-all and
count-some.
The count-all algorithms count all the large sequences, including non-maximal
sequences. The non-maximal sequences must then be pruned out (in the maximal
phase). AprioriAll listed below is a count-all algorithm, based
on the Apriori algorithm for finding large itemsets presented in chapter2.
Apriori- Some is a count-some algorithm. The intuition behind these
algorithms is that since we are only interested in maximal sequences, we
can avoid counting sequences which are contained in a longer sequence if
we first count longer sequences. However, we have to be careful not to
count a lot of longer sequences that do not have minimum support. Otherwise,
the time saved by not counting sequences contained in a longer sequence
may be less than the time wasted counting sequences without minimum support
that would never have been counted because their subsequences were not
large.
L1
= large 1-sequences; // Result of litemset phase
for ( k = 2; Lk-1
0; k++) do
begin
The algorithm is given above. In each pass, we use the large sequences from the previous pass to generate the candidate sequences and then measure their support by making a pass over the database. At the end of the pass, the support of the candidates is used to determine the large sequences. In the first pass, the output of the litemset phase is used to initialize the set of large 1-sequences. The candidates are stored in hash-tree to quickly find all candidates contained in a customer sequence.
Apriori Candidate Generation
The apriori-generate function takes as argument Lk-1, the set of all large (k-1)-sequences. It works as follows. First join Lk-1 with Lk-1
insert into Ck
select p.litemset1 , ..., p.litemsetk-1 , q.litemsetk-1
from Lk-1 p, Lk-1 q
where p.litemset1 = q.litemset1 , . . .,
p.litemsetk-2 = q.litemsetk-2 ;
Next delete all sequences c Ck such that some (k-1)-subsequence of c is not in Lk-1
Example
Consider a database with the customer-sequences shown below in Fig4.1. We have not shown the original database in this example. The customer sequences are in transformed form where each transaction has been replaced by the set of litemsets contained in the transaction and the litemsets have been replaced by integers. The minimum support has been specified to be 40% (i.e. 2 customer sequences). The first pass over the database is made in the litemset phase, and we determine the large 1-sequences shown in Fig. 4.2. The large sequences together with their support at the end of the second, third, and fourth passes are also shown in the same figure. No candidate is generated for the fifth pass. The maximal large sequences would be the three sequences 1 2 3 4 , 1 3 5 and 4 5 .
1 5 2 3 4
1 3 4 3 5
1} 2} 3} 4}
1} 3} 5}
4} 5}
Fig4.1: Customer Sequences
// Forward Phase
L1 = large 1-sequences; // Result of litemset phase
C1 = L1 ; // so that we have a nice loop condition
last = 1; // we last counted Clast
for ( k = 2; Ck-1 0 and Llast 0; k++) do
begin
if (Lk-1 known) then
Ck= New candidates generated from Lk-1 ;
else
Ck= New candidates generated from Ck-1 ;
if (k == next(last) ) then begin
foreach customer-sequence c in the database do
Increment the count of all candidates in Ck that are contained in c.
Lk = Candidates in Ck with minimum support.
last = k;
end
end
// Backward Phase
for ( k-- ; k >=1; k==) do
if (Lk not found in forward phase) then begin
Delete all sequences in Ck contained in some Li , i>k;
foreach customer-sequence in DT do
Increment the count of all candidates in Ck that are contained in c.
Lk = Candidates in Ck with minimum support.
end
else // Lk already known
Delete all sequences in Lk contained in some Li , i > k.
Answer = k Lk ;
Let hitk denote the ratio of the number of large k-sequences to the number of candidate k-sequences (i.e., |Lk | / |Ck|). The next function we used in the experiments is given below. The intuition behind the heuristic is that as the percentage of candidates counted in the current pass which had minimum support increases, the time wasted by counting extensions of small candidates when we skip a length goes down.
function next(k: integer)
begin
if (hitk < 0.666) return k + 1;
elsif (hitk <0.75) return k + 2;
elsif (hitk < 0.80) return k + 3;
elsif (hitk < 0.85) return k + 4;
else return k + 5;
end
We use the apriori-generate function given above to generate new candidate sequences. However, in the kth pass, we may not have the large sequence set Lk-1 available as we did not count the (k-1)-candidate sequences. In that case, we use the candidate set Ck-1 to generate Ck. Correctness is maintained because Ck-1 Lk-1
In the backward phase, we count sequences for the lengths we skipped over during the forward phase, after first deleting all sequences contained in some large sequence. These smaller sequences cannot be in the answer because we are only interested in maximal sequences. We also delete the large sequences found in the forward phase that are non-maximal.
Example
Using again the database used in the example for the AprioriAll algorithm, we find the large 1-sequences (L1) shown in Fig. 4.2 below in the litemset phase (during the first pass over the database). Take for illustration simplicity, f(k) = 2k. In the second pass, we count C2 to get L2 (Fig. 4.2). After the third pass, apriori-generate is called with L2 as argument to get C3 . We do not count C3 , and hence do not generate L3 . Next, apriori-generate is called with C3 to get C4. After counting C4 to get L4 (Fig. 4.2), we try generating C5, which turns out to be empty.
We then start the backward phase. Nothing gets deleted from L4 since there are no longer sequences. We had skipped counting the support for sequences in C3 in the forward phase. After deleting those sequences in C3 that are subsequences of sequences in L4, i.e., subsequences of 1 2 3 4 , we are left with the sequences 1 3 5 and 3 4 5. These would be counted to get 1 3 5 as a maximal large 3-sequence. Next, all the sequences in L2 except 4 5 are deleted since they are contained in some longer sequence. For the same reason, all sequences in L1 are also deleted.
L 1
| 1-Sequences | Support |
| 1 | 4 |
| 2 | 2 |
| 3 | 4 |
| 4 | 4 |
| 5 | 4 |
L 2
| 2-Sequences | Support |
| 1 2 | 2 |
| 1 3 | 4 |
| 1 4 | 3 |
| 1 5 | 3 |
| 2 3 | 2 |
| 2 4 | 2 |
| 3 4 | 3 |
| 3 5 | 2 |
| 4 5 | 2 |
L 3
| 3-Sequences | Support |
| 1 2 3 | 2 |
| 1 2 4 | 2 |
| 1 3 4 | 3 |
| 1 3 5 | 2 |
| 2 3 4 | 2 |
L 4
| 4-Sequences | Support |
| 1 2 3 4 | 2 |
Averaging an algorithm's performance over all target concepts, assuming they are all equally likely, would be like averaging a car's performance over all possible terrain types, assuming they are all equally likely. This assumption is clearly wrong in practice; for a given domain, it is clear that not all concepts are equally probable.
In medical domains, many measurements (attributes) that doctors have developed over the years tend to be independent: if the attributes are highly correlated, only one attribute will be chosen. In such domains, a certain class of learning algorithms might outperform others. For example, Naive-Bayes seems to be a good performer in medical domains (Kononenko 1993). Quinlan (1994) identifies families of parallel and sequential domains and claims that neural-networks are likely to perform well in parallel domains, while decision-tree algorithms are likely to perform well in sequential domains. Therefore, although a single induction algorithm cannot build the most accurate classifiers in all situations, some algorithms will perform better in specific domains.
This field is still in it's infancy and is constantly evolving. The first people who gave a serious thought to the problem of data mining were those researching in the Database field , since they were the first to face this problem. Whereas most of the tools and techniques used for data mining come from other related fields like pattern recognition, statistics and complexity theory. It is only recently that the researchers of these various fields have been interacting to solve the mining issue.Data Size
Most of the traditional data mining techniques failed because of the sheer size of the data. New techniques will have to be developed to store this huge data. Any algorithm that is proposed for mining data will have to account for out of core data structures. Most of the existing algorithms haven't addressed this issue. Some of the newly proposed algorithms like parallel algorithms (sec. 2.4) are now beginning to look into this.
Data Noise
Most of the algorithms assume the data to be noise-free. As a result, the most time-consuming part of solving problems becomes data preprocessing. Data formatting and experiment/result management are frequently just as time-consuming and frustrating.
The concept of noisy data can be understood by the example of mining logs. A real life scenario can be if one wants to mine information from web logs. A user may have gone to a web site by mistake - incorrect URL or incorrect button press. In such a case, this information is useless if we are trying to deduce a sequence in which the user accessed the web pages. The logs may contain many such data items . These data items constitute data noise. A database may constitute upto 30-40% such Noisy data and pre-processing this data may take up more time than the actual algorithm execution time.
Listed below are all the web sites that I referred to for this project report. Some of these sites containing research papers of the various teams that I referred to for my report (see the References).
University / Non-profit Research Groups