Abstract
Autism spectrum disorder (ASD) is a heritable and lifelong neurodevelopmental disorder (NDD) with complicated aetiology and causes. It is globally prevalent, and affects one in 59 children in the United States. Though currently recognized as the most effective clinical route to ASD treatment, early diagnoses and interventions rely on a team of medical expertise with diagnostic instruments that are both time-consuming and clinically demanding. Due to the prevalence of ASD and limited clinical resource, they are not widely applicable. In addition, human assessment is subjective and tends to be inconsistent, and is also episodic.
To address the aforementioned challenges, this work presents a novel framework for automatic and quantitative screening of autism spectrum disorder (ASD). It differentiates itself with three unique features: first, it proposes an ASD screening with privileged modality framework that integrates information from two behavioral modalities during training and improves the performance on each single modality at testing. The proposed framework does not require overlap in subjects between the modalities. Second, it develops the first computational model to classify people with ASD using a photo-taking task where subjects freely explore their environment in a more ecological setting. Photo-taking reveals attentional preference of subjects, differentiating people with ASD from healthy people, and is also easy to implement in real-world clinical settings without requiring advanced diagnostic instruments. Third, this study for the first time takes advantage of the temporal information in eye movements while viewing images, encoding more detailed behavioral differences between ASD people and healthy controls. Experiments show that our ASD screening models can achieve superior performance, outperforming the previous state-of-the-art methods by a considerable margin. Moreover, our framework using diverse modalities demonstrates performance improvement on both the photo-taking and image-viewing tasks, providing a general paradigm that takes in multiple sources of behavioral data for a more accurate ASD screening. The framework is also applicable to various scenarios where one-to-one pairwise relationship is difficult to obtain across different modalities.
Resources
Paper
Shi Chen and Qi Zhao, "Attention-based Autism Spectrum Disorder Screening with Privileged Modality," in ICCV 2019. [pdf] [bib] [poster]
Code
The GitHub repository provides the code for performing our experiments on the publicly available Saliency4ASD dataset.
Gaze Differences between ASD and Controls
The visual attention network is pervasive in the brain that many NDDs are associated with atypical attention towards visual stimuli. Our experiments highlight the significant differences between the gaze patterns of ASDs and Controls in both spatial (I-III) and temporal (IV-V) domains.

Model for ASD Screening with Photo-taking (top) and Image Viewing (bottom)
The attention patterns captured in the photo-taking and image-viewing paradigms are processed with CNN+LSTM style networks to encode the spatiotemporal information for ASD screening.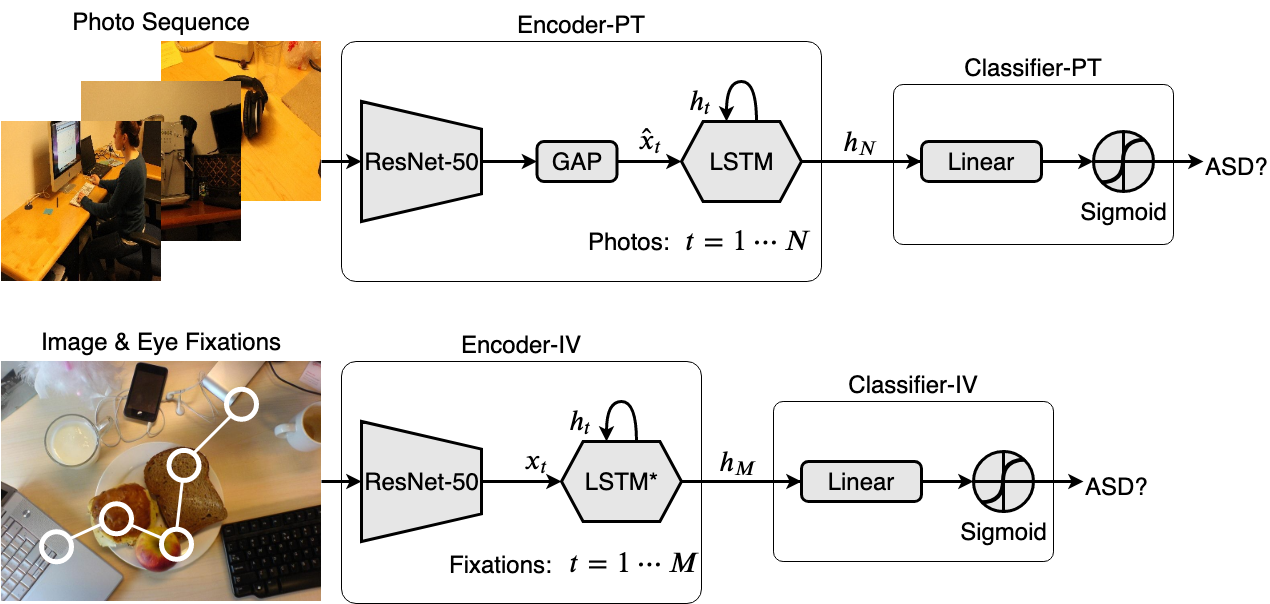
Multi-modal Distillation Through a Shared Space
To enables models to learn from diverse types of behavioral data, we propose a distillation method for transferring multi-modal knowledge through a space shared between models of different modalities. Our method consists of three training phases, and each phase focus on optimizing different parts of the models (highlighted in green).
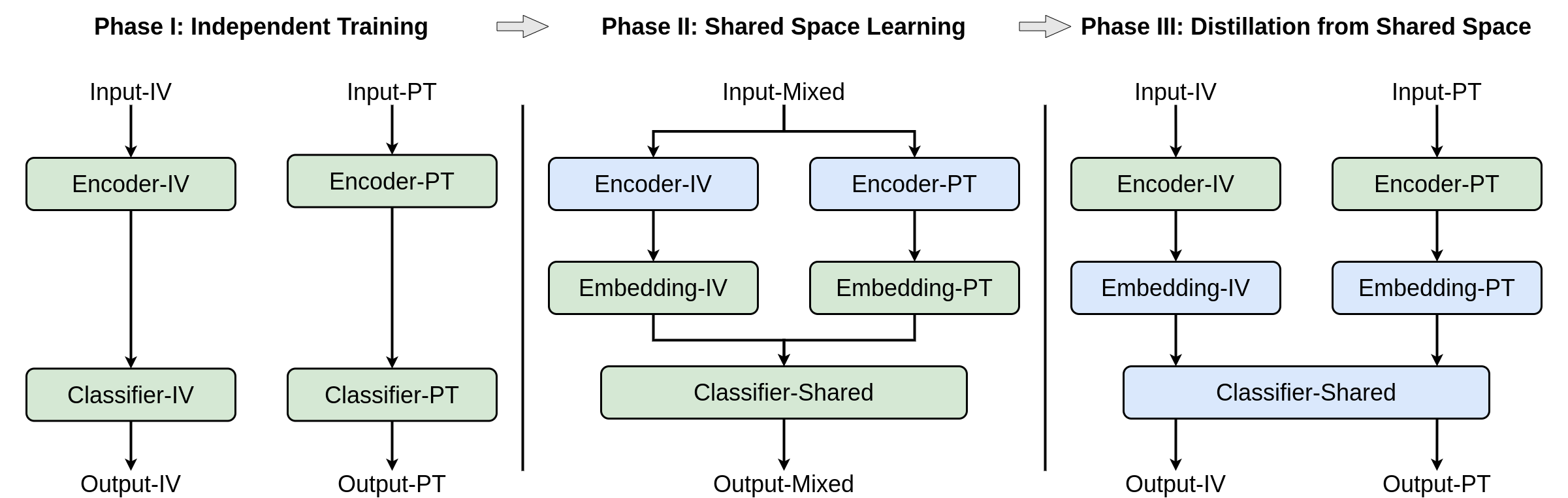
Phase I: Training on two modalities independently to establish reasoning performance
Phase II: Freezing the feature encoders for the two modalities, and learning a shared space via joint optimization on both modalities with the same classifier.
Phase III: Freezing the classifier, and boosting the feature encoders with knowledge on multi-modality learned in the shared space.
Quantitative Results
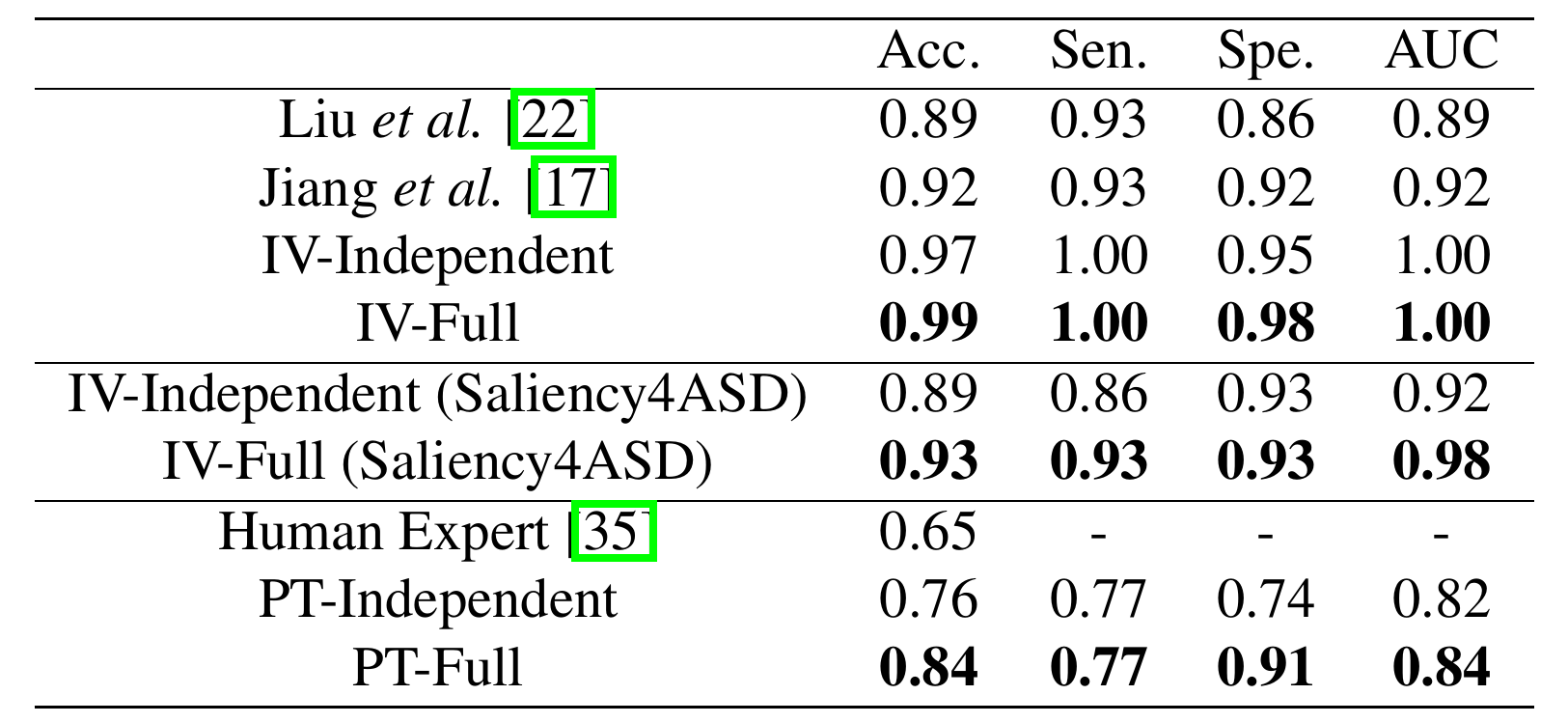
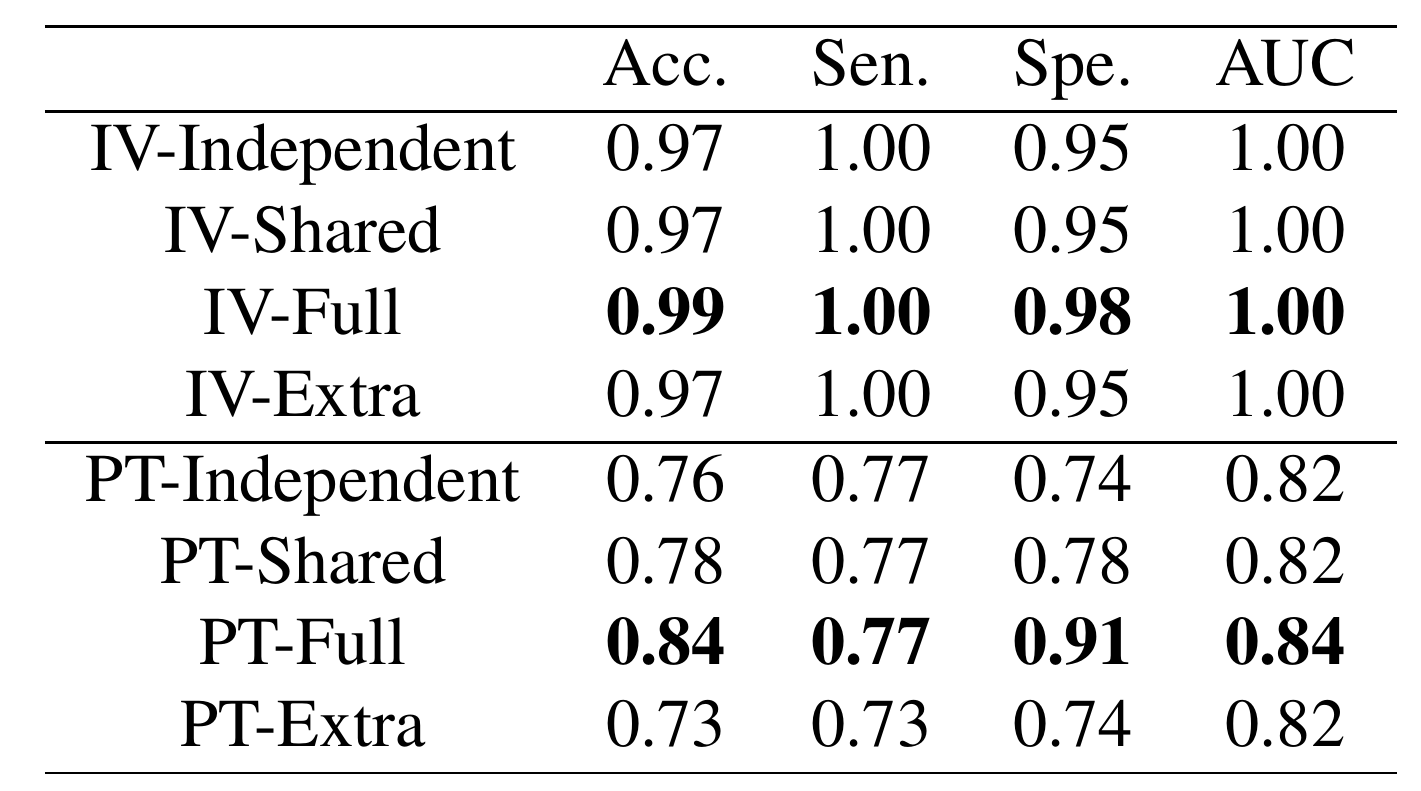
Qualitative Results
To validate the effectiveness of the proposed multi-modal distillation, we coduct a cross-modal matching experiments and visualize the closest samples (measured by the cosine similarity between the features) from different modalities. Results show that, compared to learning on modalities independently (Independent), the proposed method (Shared) is able to better correlate the two modalities based on their semantic meanings.
