Explicit Knowledge Incorporation for Visual Reasoning
Yifeng Zhang*, Ming Jiang*, Qi Zhao
University of Minnesota
Abstract
Existing explainable and explicit visual reasoning methods only perform reasoning based on visual evidence but do not take into account knowledge beyond what is in the visual scene. To addresses the knowledge gap between visual reasoning methods and the semantic complexity of real-world images, we present the first explicit visual reasoning method that incorporates external knowledge and models high-order relational attention for improved generalizability and explainability. Specifically, we propose a knowledge incorporation network that explicitly creates and includes new graph nodes for entities and predicates from external knowledge bases to enrich the semantics of the scene graph used in explicit reasoning. We then create a novel Graph-Relate module to perform high-order relational attention on the enriched scene graph. By explicitly introducing structured external knowledge and high-order relational attention, our method demonstrates significant generalizability and explainability over the state-of-the-art visual reasoning approaches on the GQA and VQAv2 datasets.
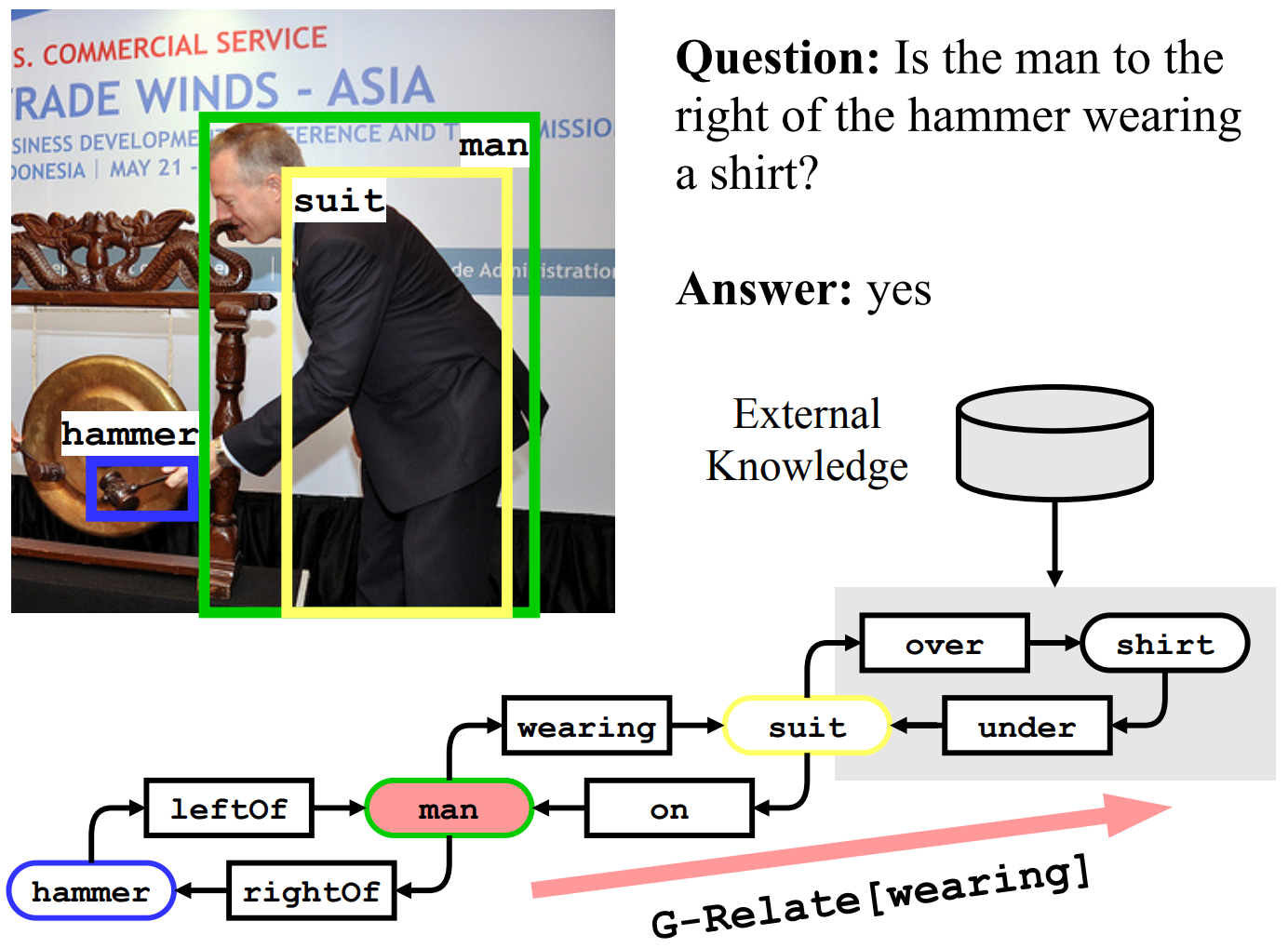
Explicit visual reasoning methods often fail when the observation does not provide sufficient knowledge. Our method addresses this problem by generating scene graphs with explicit knowledge incorporation (e.g., suit-over-shirt) and inferring highorder relations (e.g., man-wearing-suit-over-shirt) with a novel G-Relate neural module.
Method
In this work, to achieve generalizability and explainability in visual reasoning, we propose an explainable and explicit visual reasoning method based on knowledge incorporation and high-order relational attention. It depicts two major advantages over existing approaches:
- Existing visual reasoning studies either implicitly embed external knowledge as language features or propagate information from external knowledge graphs into a scene graph with static topology, which is not able to address undetected objects or missing concepts from the visual scene. Differently, in this work, we propose a Knowledge-Incorporation Network (KI-Net) that explicitly incorporates commonsense knowledge from an external knowledge graph into the scene graph by adding entities and predicates as new nodes. This enriched scene graph offers richer semantics enabling generalizable and explainable reasoning.
- Eexisting methods depend on the detected binary relations but lack a mechanism to infer high-order relations between distant nodes in the scene graph. We address this challenge by designing a novel Graph-Relate (G-Relate) module that enables high-order relational reasoning. This allows our model to efficiently transfer attention to non-adjacent graph nodes and answer the question correctly.
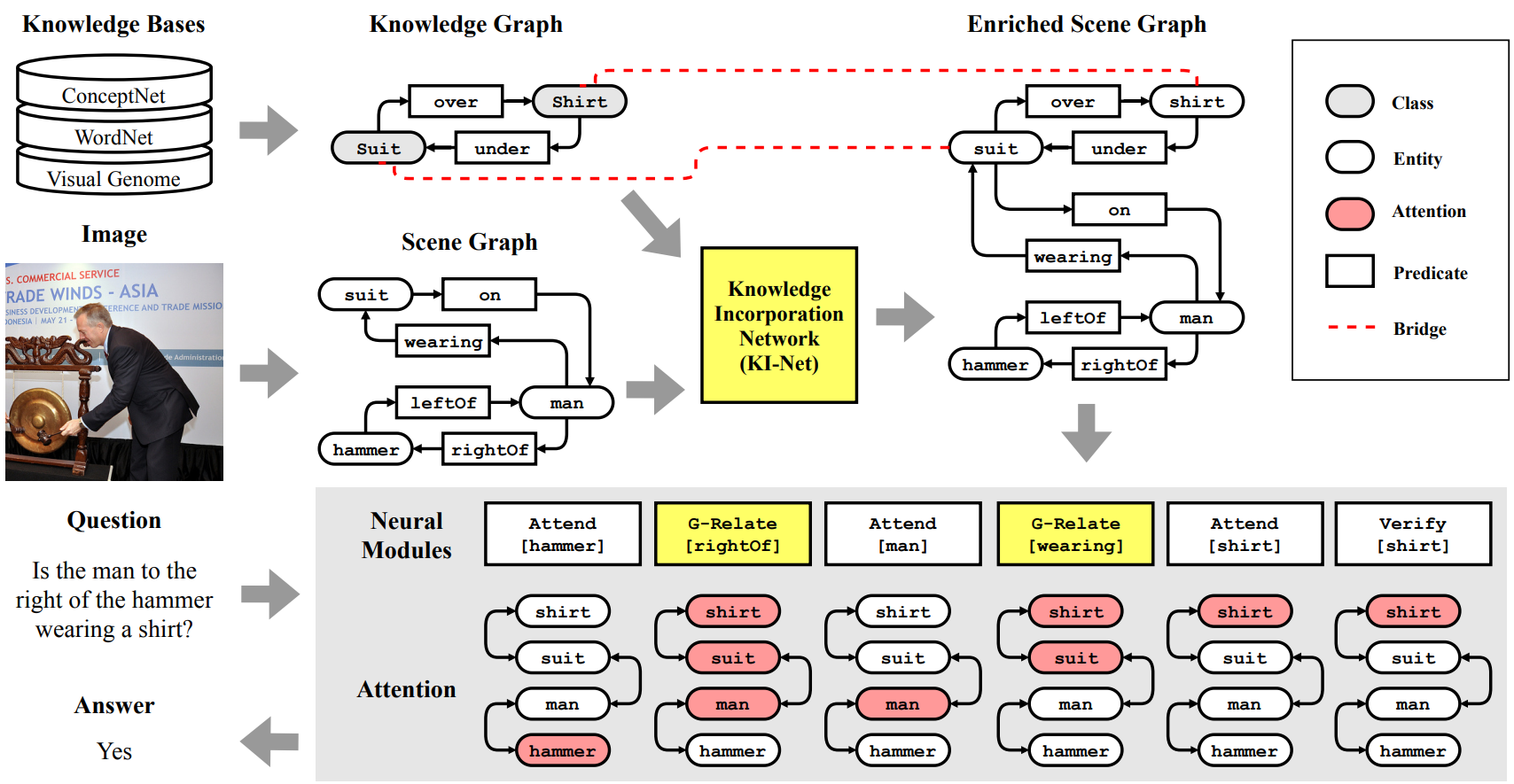
Overview of our proposed method. Our main contributions, the Knowledge Incorporation Network (KI-Net) and the Graph-Relate (G-Relate) module, are highlighted in yellow. Red nodes indicate the current attention.
Results
We demonstrate our method with experiments on the GQA and VQAv2 datasets. Our method outperforms the state-of-the-art explicit reasoning methods, suggesting its superior ability to generate neural modules to explicitly reason over the enriched scene graph. Qualitative examples show that the complex reasoning process can be completely traced across multiple graph nodes:
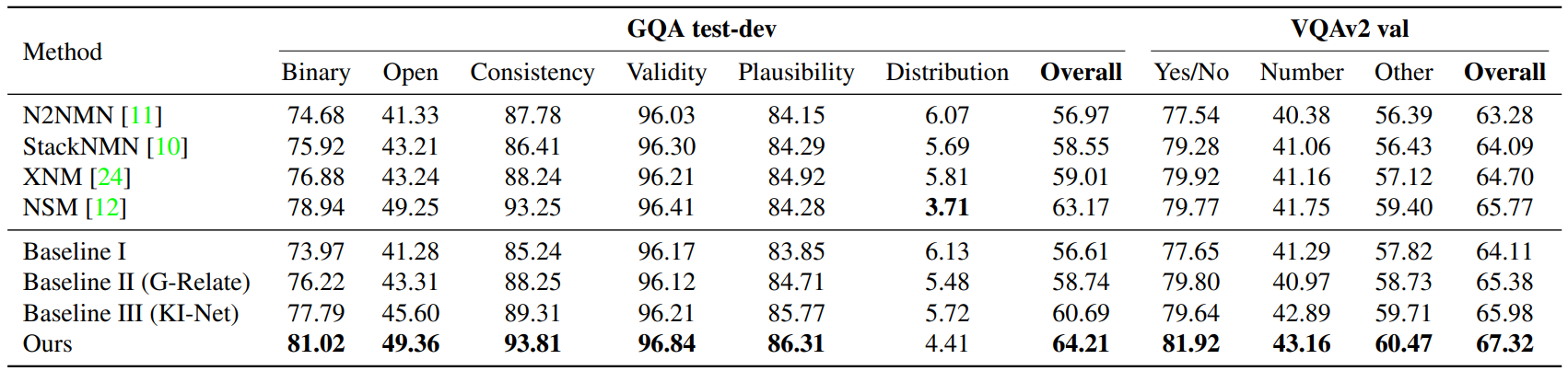
Quantitative results on the GQA and VQAv2 datasets. The best results are highlighted in bold.

Qualitative examples of our method with the incorporated knowledge and the generated neural modules. Highlighted entities and predicates are incorporated from external knowledge.
Download Links
Please cite the following paper if you use our dataset or code:
@InProceedings{Zhang_2021_CVPR,
author = {Zhang, Yifeng and Jiang, Ming and Zhao, Qi},
title = {Explicit Knowledge Incorporation for Visual Reasoning},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2021},
pages = {1356-1365}
}Acknowledgment
This work is supported by National Science Foundation grant 1908711.