Abstract
A significant body of literature on saliency modeling predicts where humans look in a single image or video. Besides the scientific goal of understanding how information is fused from multiple visual sources to identify regions of interest in a holistic manner, there are tremendous engineering applications of multi-camera saliency due to the widespread of cameras. This work proposes a principled framework to smoothly integrate visual information from multiple views to a global scene map, and to employ a saliency algorithm incorporating high-level features to identify the most important regions by fusing visual information. The proposed method has the following key distinguishing features compared with its counterparts: (1) the proposed saliency detection is global (salient regions from one local view may not be important in a global context), (2) it does not require special ways for camera deployment or overlapping field of view, and (3) the key saliency algorithm is effective in highlighting interesting object regions though not a single detector is used. Experiments on several datasets confirm the effectiveness of the proposed principled framework.
Resources
Paper
Yan Luo, Ming Jiang, Yongkang Wang, and Qi Zhao, "Multi-Camera Saliency," in IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), Volume 37, Issue 10, Pages 2057-2070, October 2015. [pdf] [bib]
Dataset MCIE (Multi-Camera Image and Eye-tracking, including images, human fixation and calibration information, coming soon...).
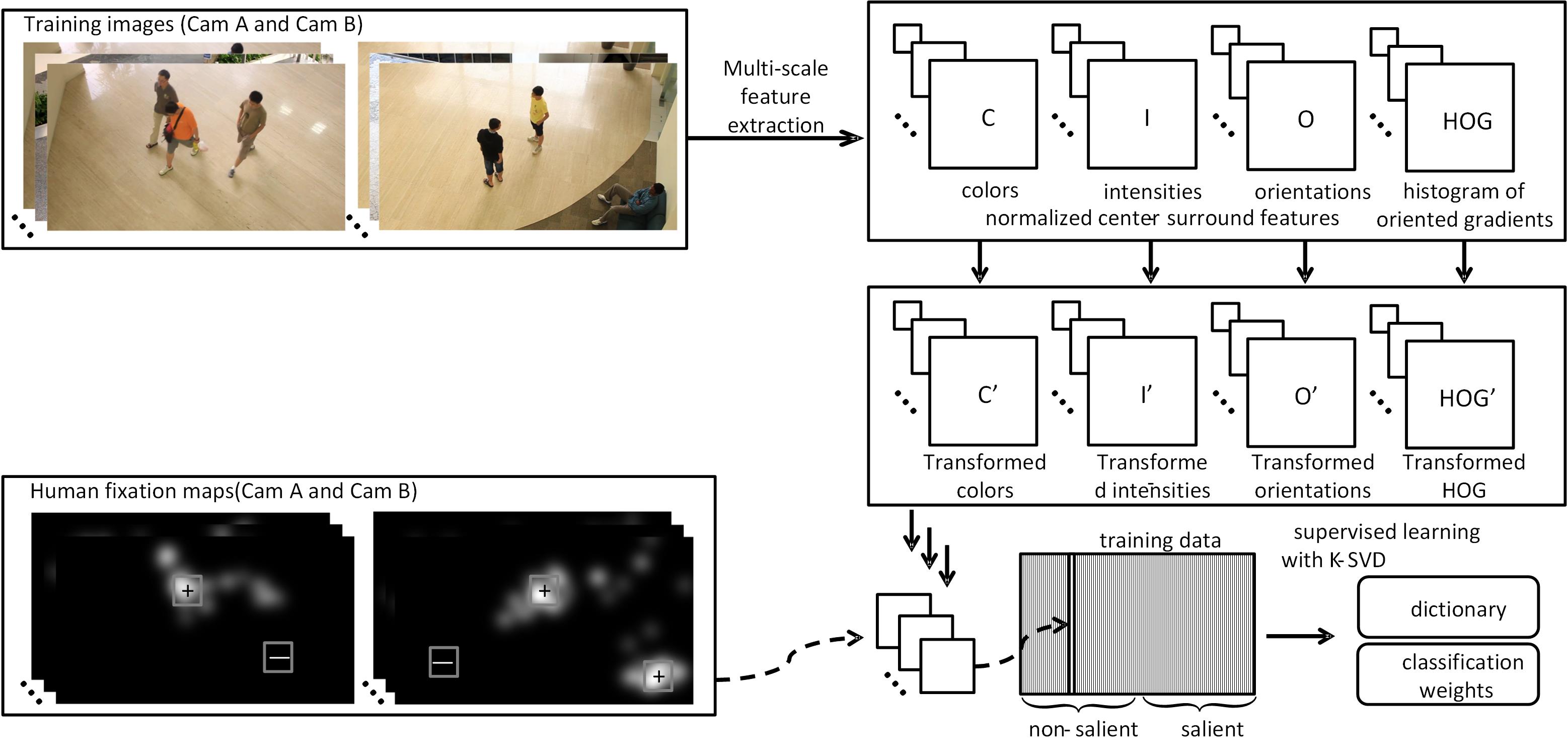
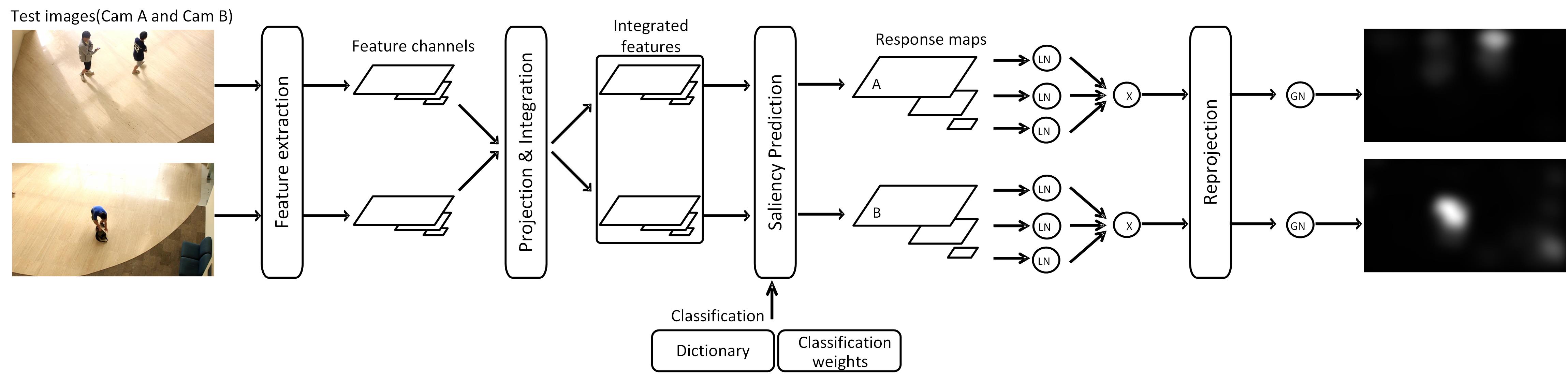
Multi-Camera Saliency Frame Work with LC-KSVD Saliency Model
Training
Prediction
Multi-Camera Image and Eye-tracking Dataset
Features
MCIE contains two-view subset and three-view subset, which are composed of 2*450 and 3*450 (respectively) synchronized images with human fixation and calibration information (for transformation purpose).

Experiments
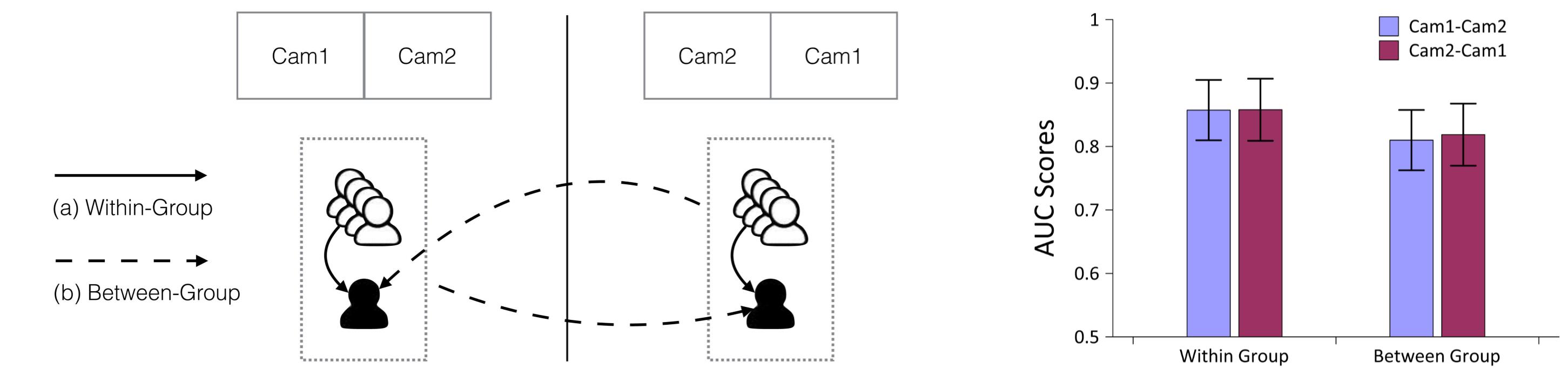
Human Behavioral Analysis
To compare the human eye-fixations between different experimental settings, we computed the inter-subject AUC scores by evaluating each subject��s fixations against the compared subject groups. For more details, please refer to the paper.
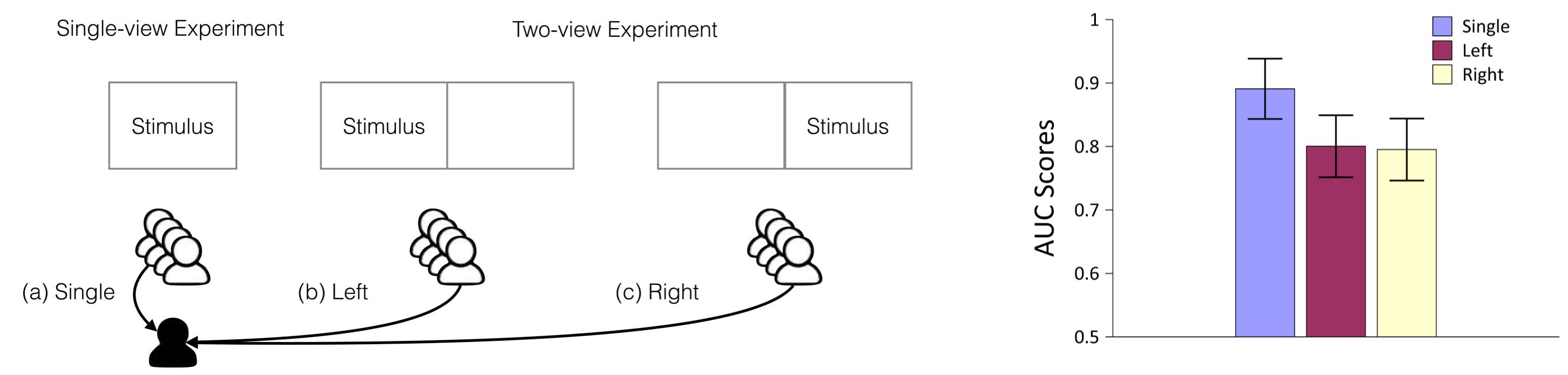
To investigate the effect of the image placement on the viewing patterns, we categorized the two-view fixations into two groups, according to the order of the two views, i.e., Cam1-Cam2 and Cam2-Cam1.
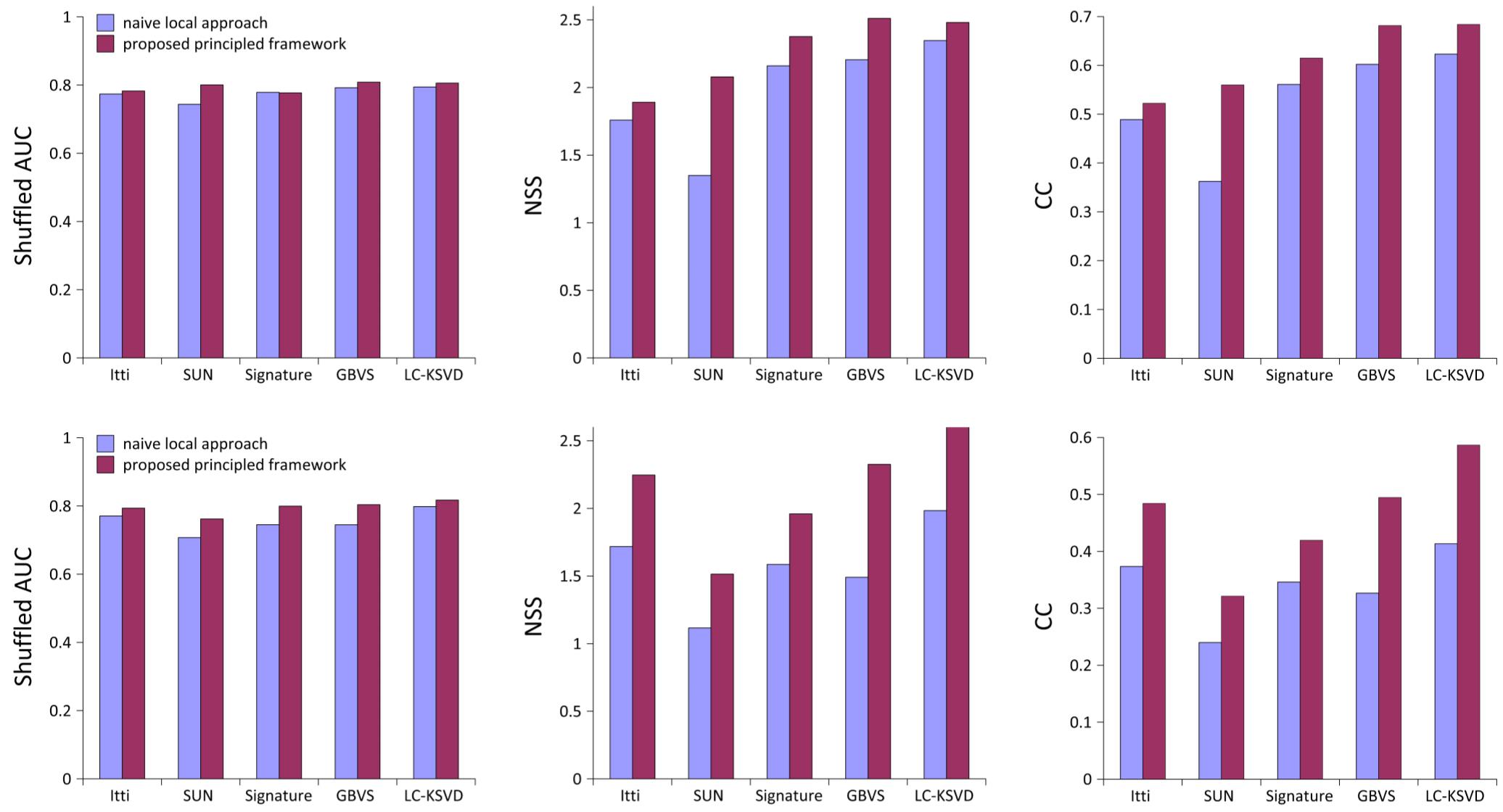
Quantitative Performance
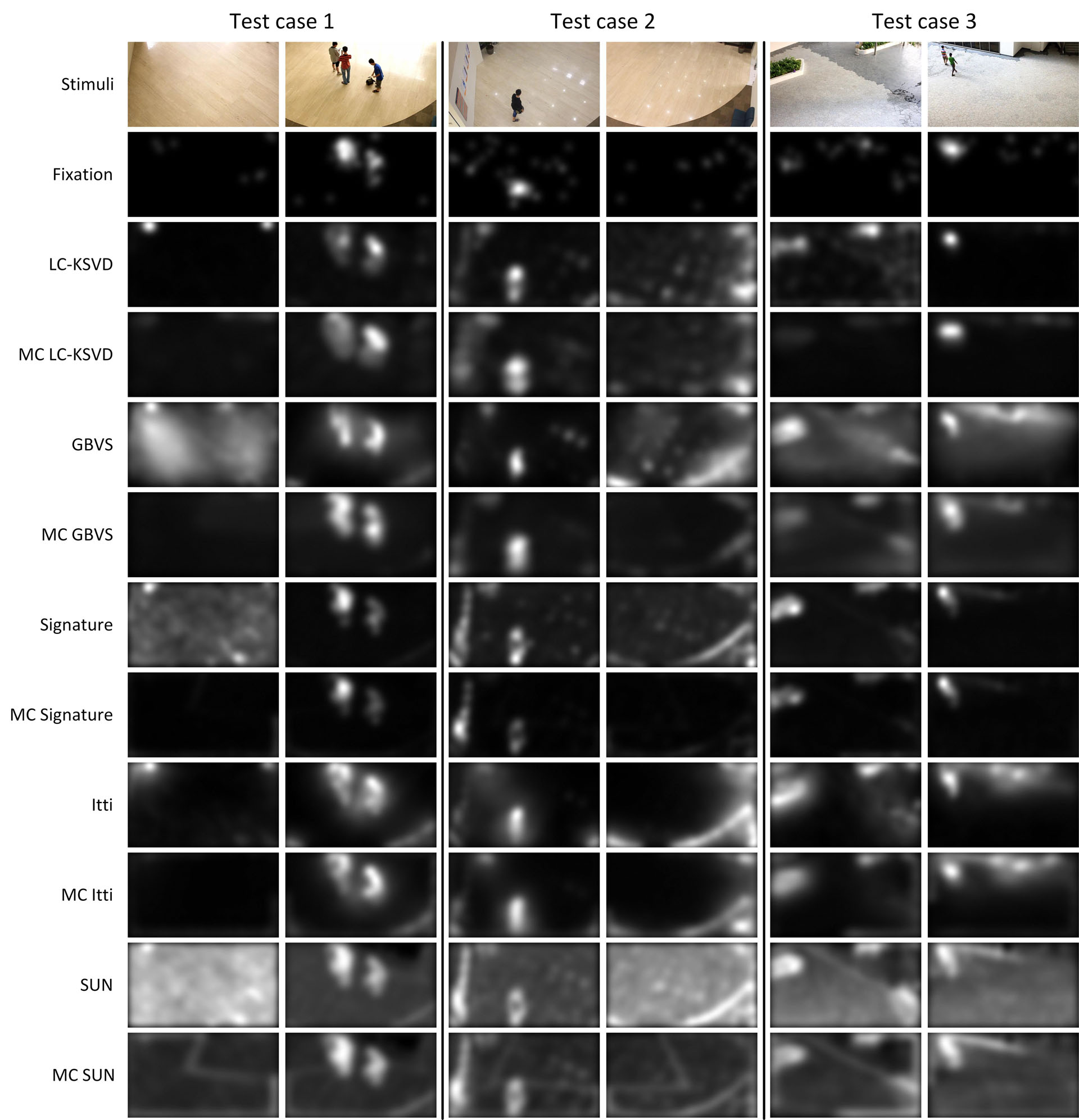
We evaluated the multi-camera saliency framework with LC-KSVD, GBVS, Signature, SUN and Itti with 10-fold cross-validation on MCIE dataset. (Top row: two-view subset, and bottom row: three-view subset.)
Quanlitative Results