Abstract
Recent surge of Convolutional Neural Networks (CNNs) has brought successes among various applications. However, these successes are accompanied by a significant increase in computational cost and the demand for computational resources, which critically hampers the utilization of complex CNNs on devices with limited computational power. We propose a feature representation based layer-wise pruning method that aims at reducing complex CNNs to more compact ones with equivalent performance. Different from previous parameter pruning methods that conduct connection-wise or filter-wise pruning based on weight information, our method determines redundant parameters by investigating the features learned in the convolutional layers and the pruning process is operated at a layer level. Experiments demonstrate that the proposed method is able to significantly reduce computational cost and the pruned models achieve equivalent or even better performance compared to the original models.Resources
Shi Chen and Qi Zhao, "Shallowing Deep Networks: Layer-wise Pruning based on Feature Representations," TPAMI 2018. [pdf]
Identifying Redundant Layers via Feature Diagnosis
Identifying redundant layers within deep neural networks is not a trivial task, and previous pruning methods are not applicable since it is difficult to determine the importance of layers based on corresponding weight information. To detect layers that have minor contributions, we propose a new method to evaluate the feature representations of different layers. By estimating the discriminative power of the features, we are able to analyze the behaviors of different layers and thus identify redundant ones. Layers with improvement on feature representations lower than a predefined threshold (layers with transparent color in the figures) will be removed from the networks.
| Feature Diagnosis on Single-Label Classification | |||
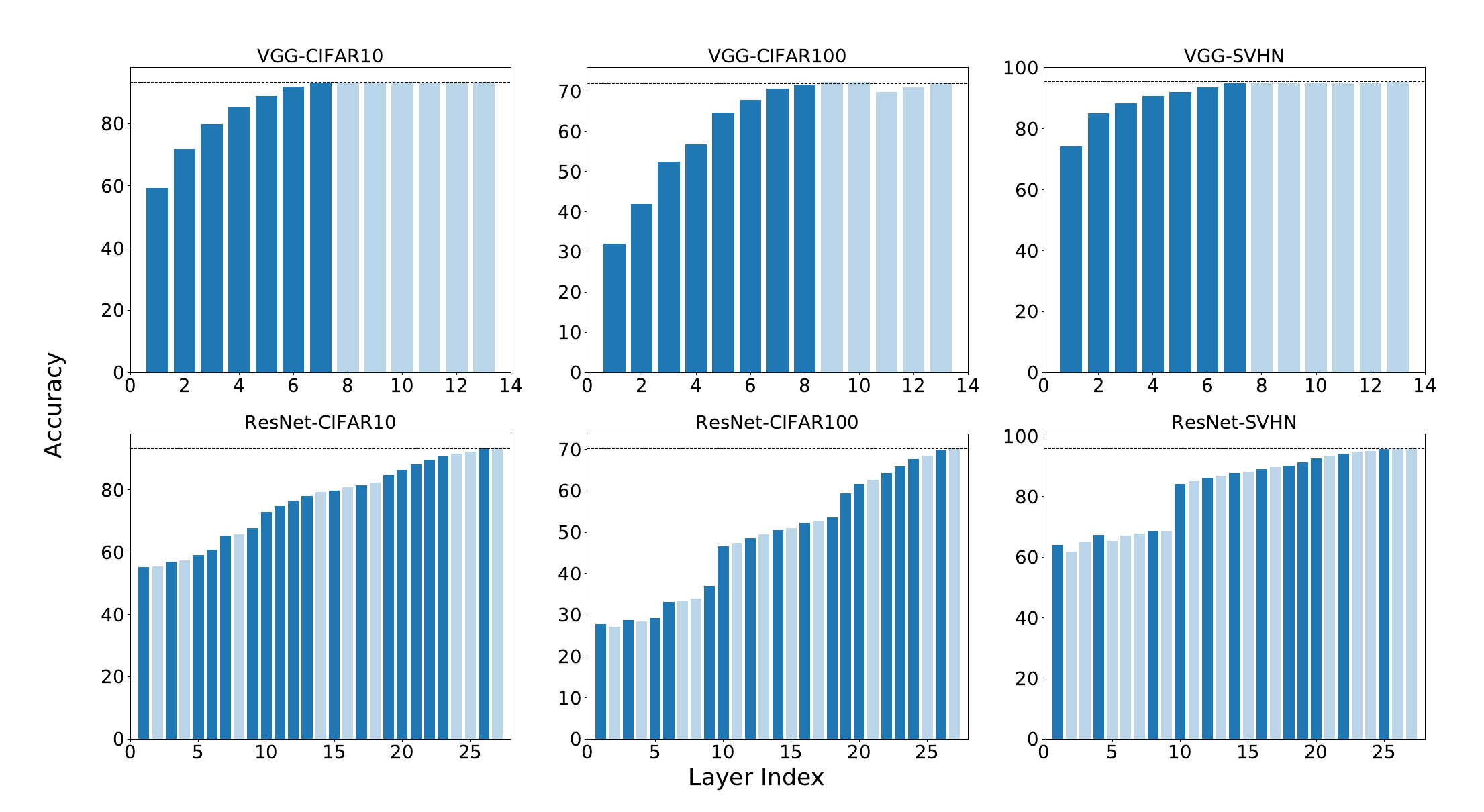 |
|||
| Feature Diagnosis on MSCOCO Multi-Label Classification | |||
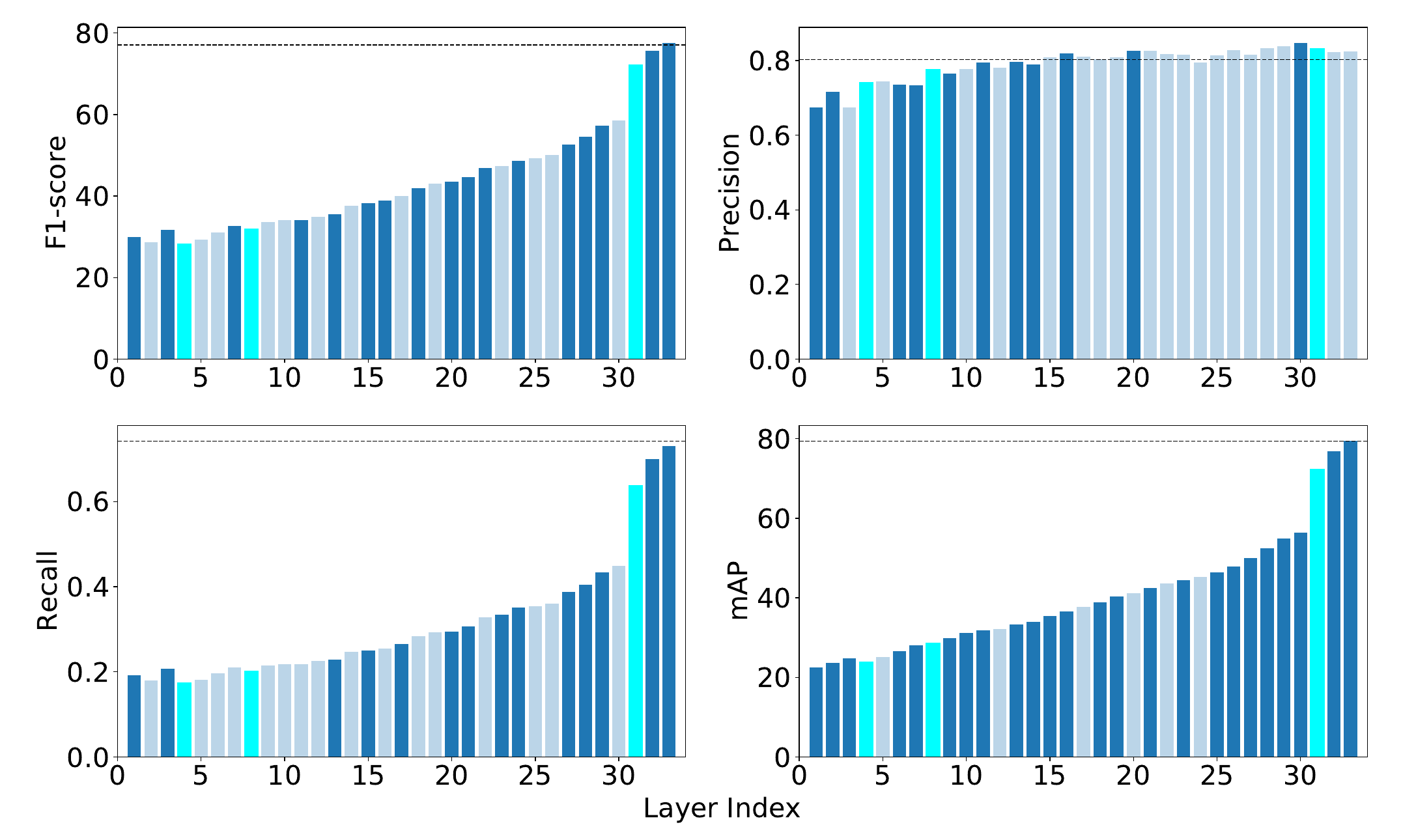 |
|||
Recovering Performance with Transfer Learning
To compensate the loss of performance resulted from layer removal, we construct a teacher-student networks, where the original model plays the role as a teacher while the pruned model acts as the student. Knolwedge distillation is utilized to transfer knowledge from teacher to student during the fine-tuning procedure.
| Illustration of the procedure of proposed layer-wise pruning. | |||
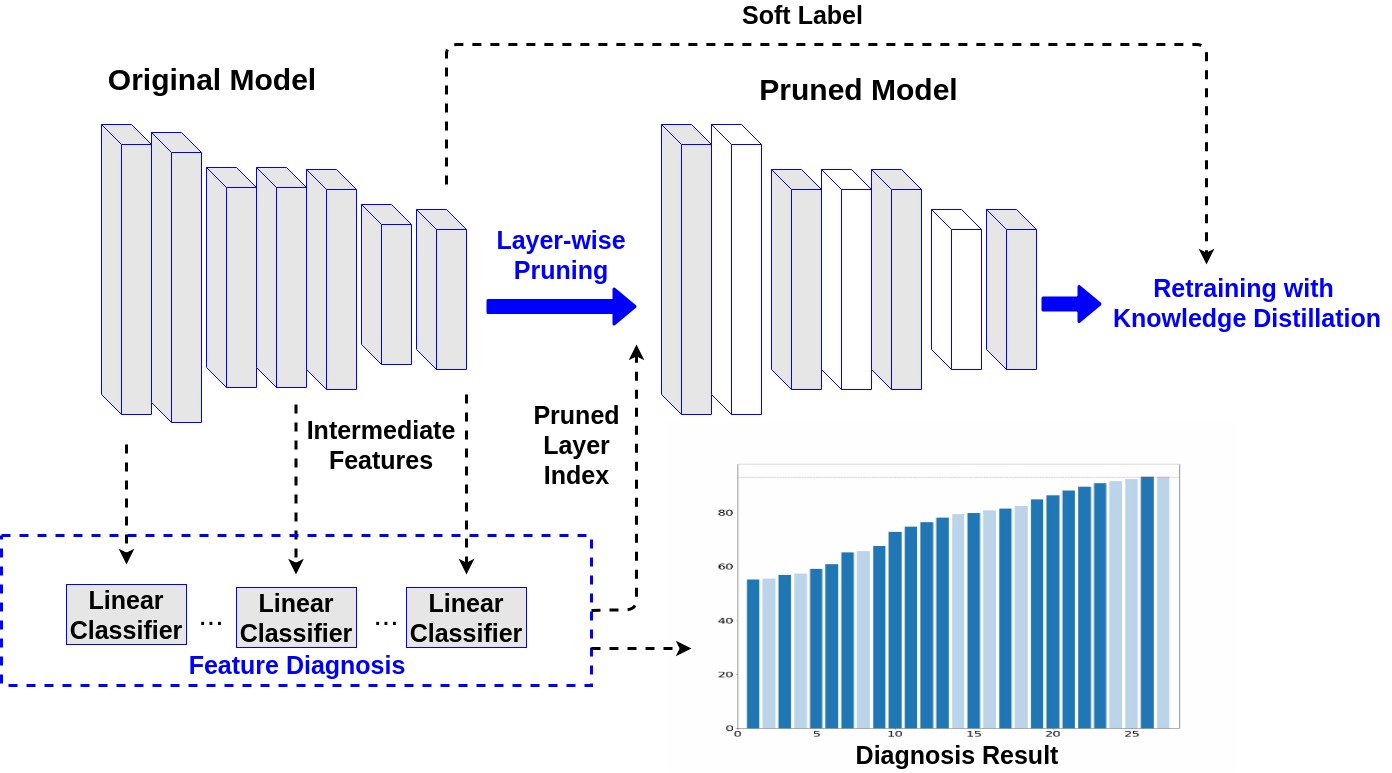 |
|||
Illustration of Pruning Results with Varying Needs
The pre-defined threshold determines the trade-off between model performance and the computational cost. For devices with limited computational resources, it is reasonable to use a larger threshold to reduce computational demand. While for the applications that require high accuracy, a lower threshold can be used to better preserve performance.
 |