Query and Attention Augmentation for Knowledge-Based Explainable Reasoning
Yifeng Zhang, Ming Jiang, Qi Zhao
Department of Computer Science and Engineering
University of Minnesota
Explainable visual question answering (VQA) models have been developed with neural modules and query-based knowledge incorporation to answer knowledge-requiring questions. Yet, most reasoning methods cannot effectively generate queries or incorporate external knowledge during the reasoning process, which may lead to suboptimal results. To bridge this research gap, we present Query and Attention Augmentation, a general approach that augments neural module networks to jointly reason about visual and external knowledge. To take both knowledge sources into account during reasoning, it parses the input question into a functional program with queries augmented through a novel reinforcement learning method, and jointly directs augmented attention to visual and external knowledge based on intermediate reasoning results. With extensive experiments on multiple VQA datasets, our method demonstrates significant performance, explainability, and generalizability over state-of-the-art models in answering questions requiring different extents of knowledge. Our source code is available at https://github.com/SuperJohnZhang/QAA.
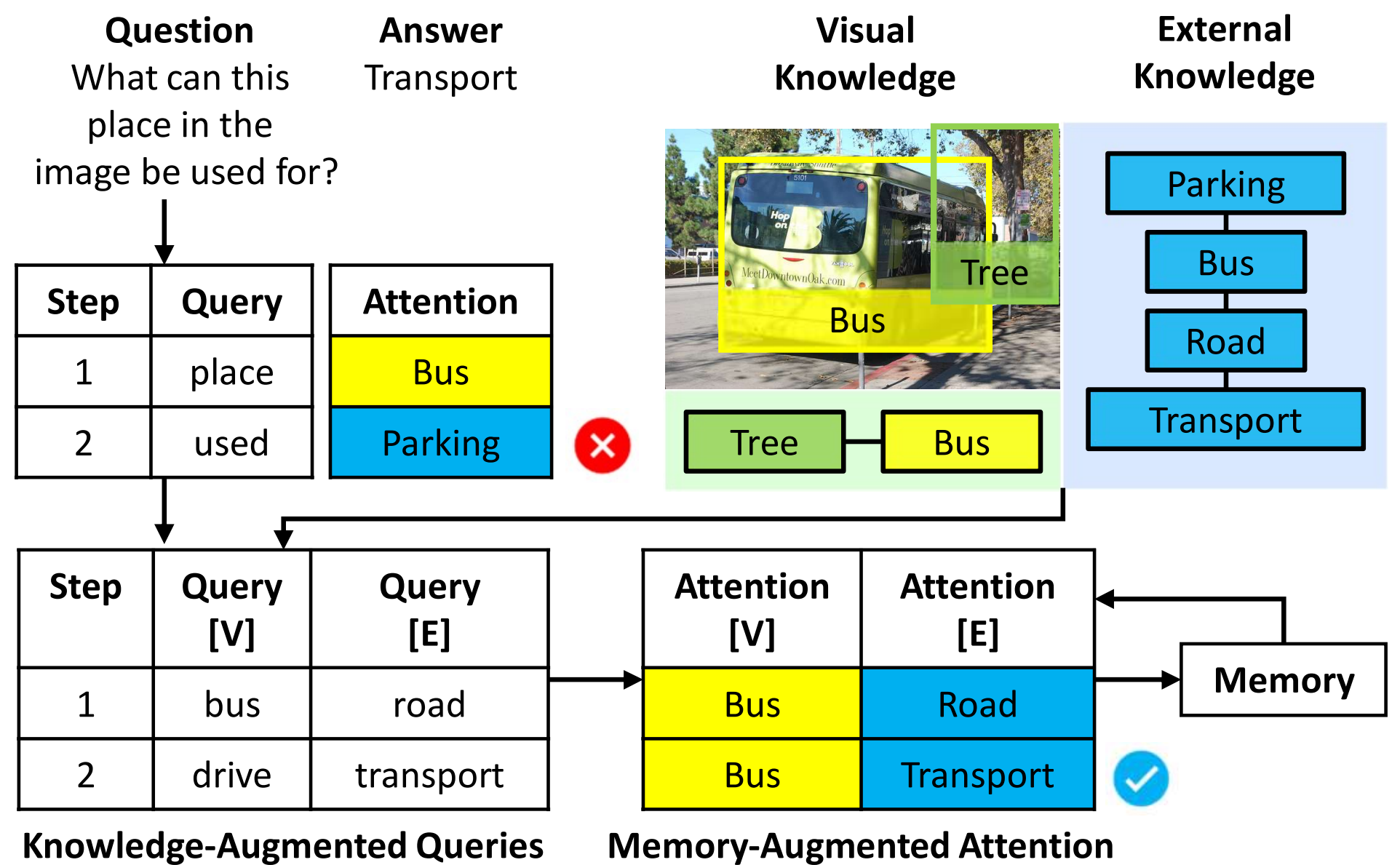
Based on neural module networks and explicit knowledge representation, we develop knowledge-augmented queries and memory-augmented attention to jointly reason about both the visual [V] and external [E] knowledge. These query and attention augmentation methods generalize explainable visual reasoning models to better answer knowledge-requiring questions.
Our work provides four novel contributions:
- To the best of our knowledge, this work is the first attempt to jointly reason about visual knowledge and external knowledge based on neural module networks.
- With reinforcement learning, we generate knowledgeaugmented queries to incorporate visual and external knowledge into the functional program.
- By sharing intermediate results between the two knowledge sources with memory-augmented attention, we enable external knowledge incorporation throughout the reasoning process.
- Our extensive experiments on multiple VQA datasets demonstrate the effectiveness, generalizability, and explainability of the proposed method.
Methodology
The goal of this work is to develop an explainable NMN method that answers questions based on the supporting evidence acquired from visual and external knowledge. The key differentiating factor of our method is its ability to interact with the two knowledge sources during the generation and execution of the program. The novelty lies in two major components: it augments the generated queries with knowledge from the visual input and the external knowledge base and jointly allocates attention to both the visual and external knowledge and augments the attention based on information sharing supported by memorized intermediate results.
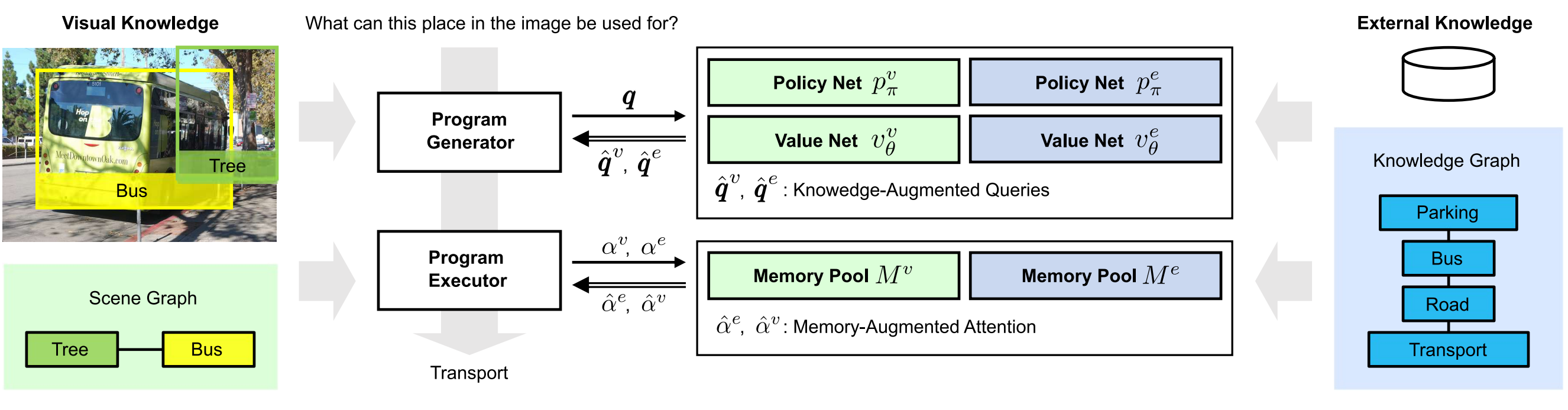
The overview of our method. First, it represents the visual input as a scene graph and the external information as a knowledge graph. Second, a program generator parses the question to predict the functional program and its corresponding base queries. Next, two reinforcement learning agents augment the base query with the visual and external knowledge, resulting in the augmented queries. Further, they are used as parameters for the program executor to allocate attention. Based on the memorized intermediate results, it computes the augmented attention vectors, which jointly consider both knowledge sources to better allocate attention. Finally, it predicts the answer based on the attended features.
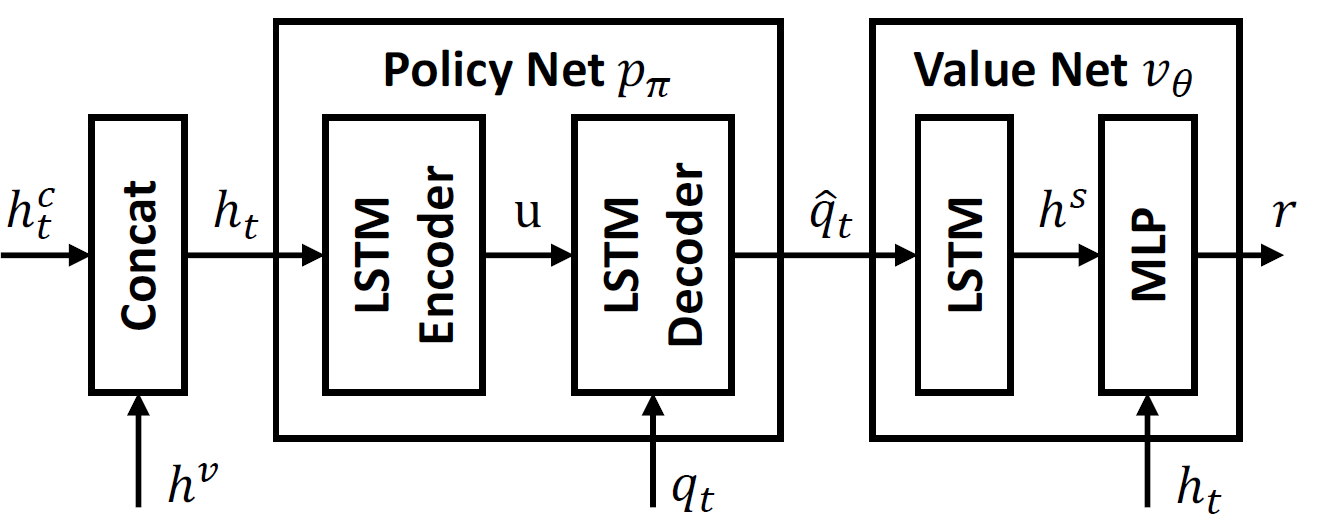
Each query augmentation agent consists of a policy network and a value network. The policy network predicts the aug- mented queries from the visual feature, the semantic vector, and the base queries. The value network evaluates the policy and predicts the total reward.
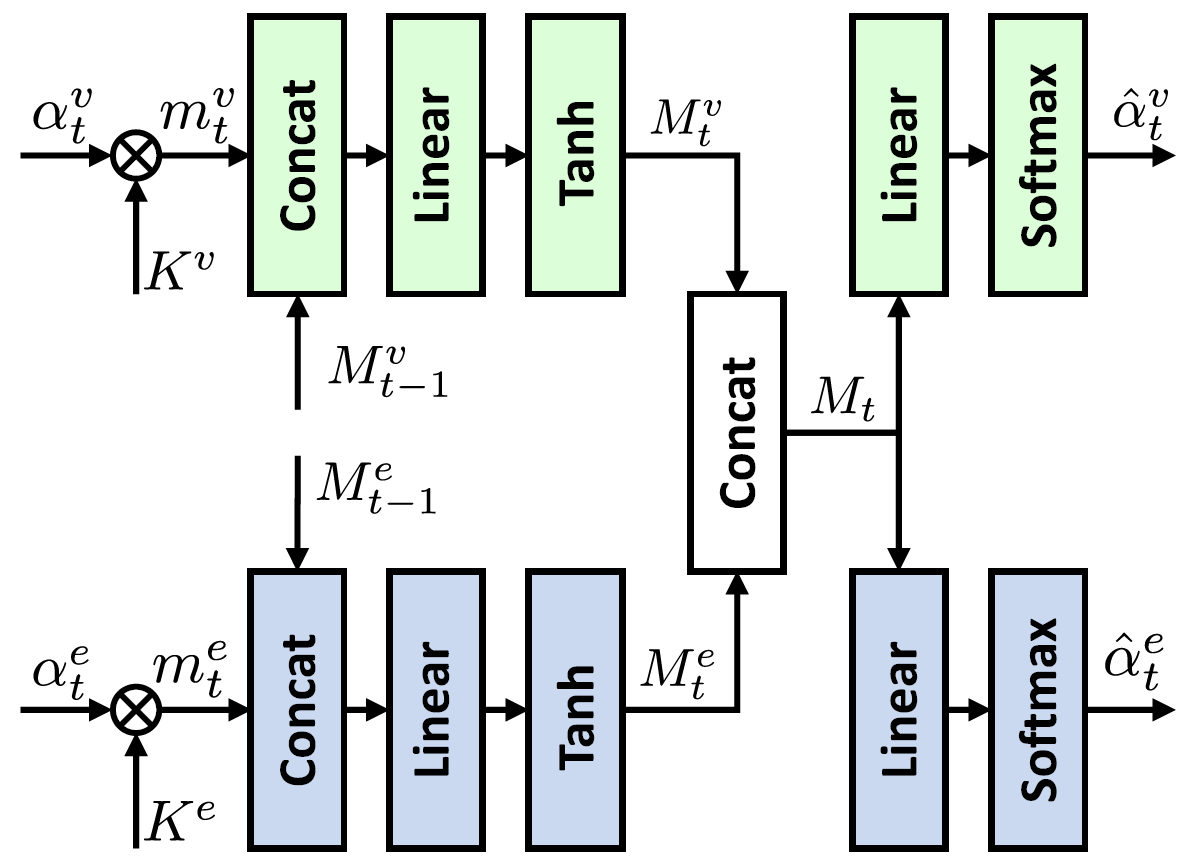
The proposed attention augmentation method processes the visual and external knowledge features with the original attention vectors to predict the memoryaugmented attention vectors.
Experiments and Results
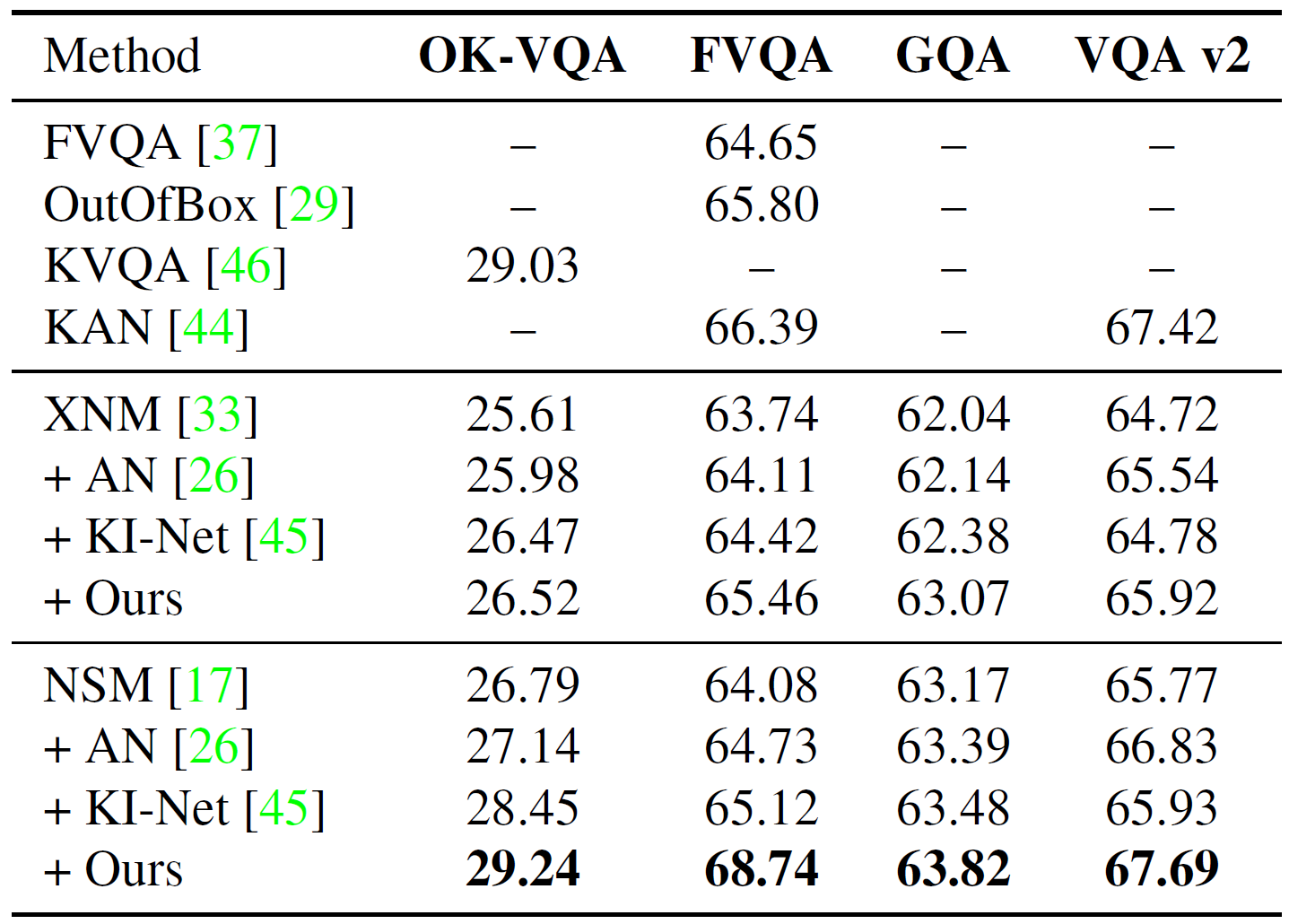
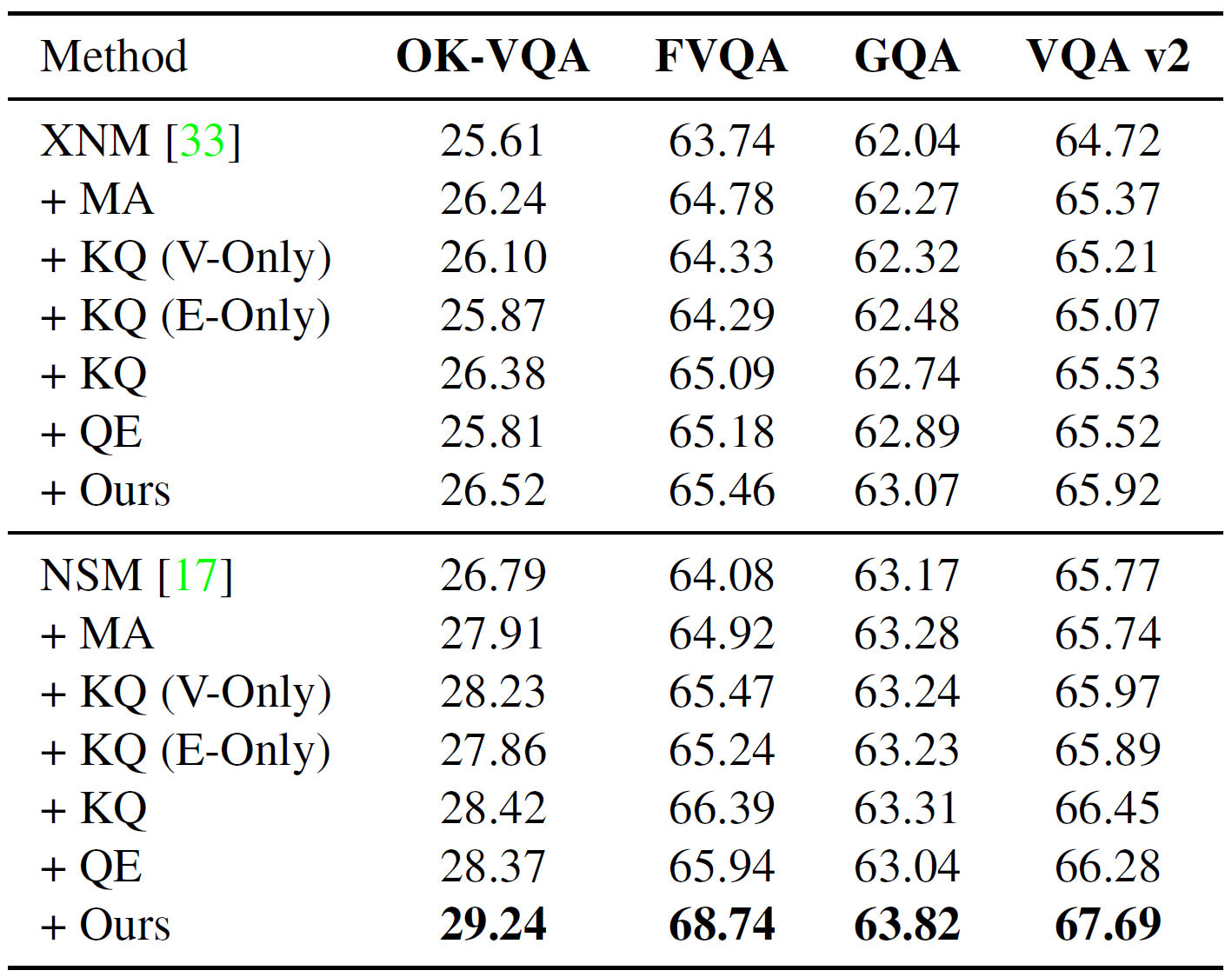
We demonstrate our method with experiments on OK-VQA, FVQA, GQA, and VQA v2 datasets. We train NMNs on the training set of datasets and evaluate them on the corresponding validation set.

Download Links
Please cite the following paper if you use our dataset or code:
@InProceedings{qaa2022,
author = {Zhang, Yifeng and Jiang, Ming and Zhao, Qi},
title = {Query and Attention Augmentation for Knowledge-Based Explainable Reasoning},
booktitle = {CVPR},
year = {2022}
}Acknowledgment
This work is supported by National Science Foundation grants 1908711 and 1849107.