REX: Reasoning-aware and Grounded Explanation
Shi Chen and Qi Zhao
Department of Computer Science and Engineering
University of Minnesota
Effectiveness and interpretability are two essential properties for trustworthy AI systems. Most recent studies in visual reasoning are dedicated to improving the accuracy of predicted answers, and less attention is paid to explaining the rationales behind the decisions. As a result, they commonly take advantage of spurious biases instead of actually reasoning on the visual-textual data, and have yet developed the capability to explain their decision making by considering key information from both modalities. This paper aims to close the gap from three distinct perspectives: first, we define a new type of multi-modal explanations that explain the decisions by progressively traversing the reasoning process and grounding keywords in the images. We develop a functional program to sequentially execute different reasoning steps and construct a new dataset with 1,040,830 multi-modal explanations. Second, we identify the critical need to tightly couple important components across the visual and textual modalities for explaining the decisions, and propose a novel explanation generation method that explicitly models the pairwise correspondence between words and regions of interest. It improves the visual grounding capability by a considerable margin, resulting in enhanced interpretability and reasoning performance. Finally, with our new data and method, we perform extensive analyses to study the effectiveness of our explanation under different settings, including multi-task learning and transfer learning.
Explaining decisions is an integral part of human communication, understanding and reasoning. This study augments visual reasoning models with the capability to explain their decision-making process by jointly incorporating key components across the visual-textual modalities.
Our work provides three novel contributions:
- A GQA-REX dataset with over 1M multi-modal explanations automatically generated by a new functional program. Instead of independently modeling explanations of a single modality without considering the reasoning process, our explanations are grounded on the reasoning process and tightly couple keywords and regions of interest.
- An explanation generation method that goes beyond the conventional paradigm of independently modeling multi-modal explanations, and leverages an explicit mapping to ground words in the visual regions based on their correlation.
- Extensive analysis of visual reasoning models under different settings, including multi-task learning and transfer learning.
Grounding Explanations on the Reasoning Process
We present typical examples of explanations in our GQA-REX dataset. The explanations are derived by progressively traversing the continuous reasoning process, and jointly incorporate key components across the visual-textual modalities.



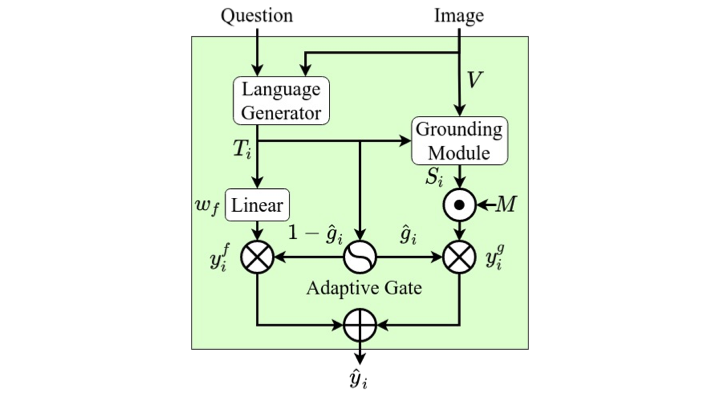
Coupling Visual-textual Explanations with an Explicit Mapping
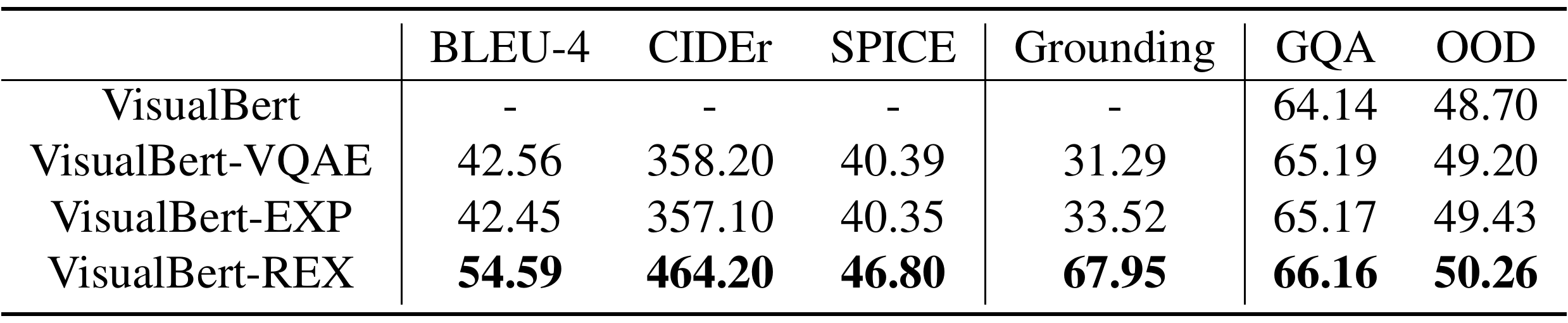
Our explanation generation model couples related components across the visual-textual modalities and constructs the explanations based on their relationships. It simultaneously improves the interpretability and reasoning performance for both multi-task learning and transfer learning.
Download Links
Please cite the following paper if you use our dataset or code:
@InProceedings{rex2022,
author = {Chen, Shi and Zhao, Qi},
title = {REX: Reasoning-aware and Grounding Explanation},
booktitle = {CVPR},
year = {2022}
}Acknowledgment
This work is supported by National Science Foundation grants 1908711 and 1849107.