Abstract
Visual attention models aim at predicting human eye fixations in natural scenes. Most state-of-the-art attention models estimate the probability distribution of fixating the eyes in a location of the image, the so called saliency maps. Yet, these models do not predict the temporal sequence of eye fixations, which may be valuable for better predicting the human eye fixations, as well as for understanding the role of the different cues during visual exploration. In this work, we present a method for predicting the sequence of human eye-fixations, that is learned from recorded human eye tracking data. We use Least-Squares Policy Iteration to learn a visual exploration policy that mimics the recorded eye-fixation examples. The model uses a different set of parameters for the different stages of visual exploration that capture the importance of the cues during the scan-path. In a series of experiments, we demonstrate the effectiveness of using Least-Squares Policy Iteration for combining multiple cues at different stages of the scan-path. The learned parameters suggest that the low-level and high-level cues (semantics) are similarly important at the first eye fixation of the scan-path, and the contribution of high-level cues keeps increasing during the visual exploration.
Results
| Learning |
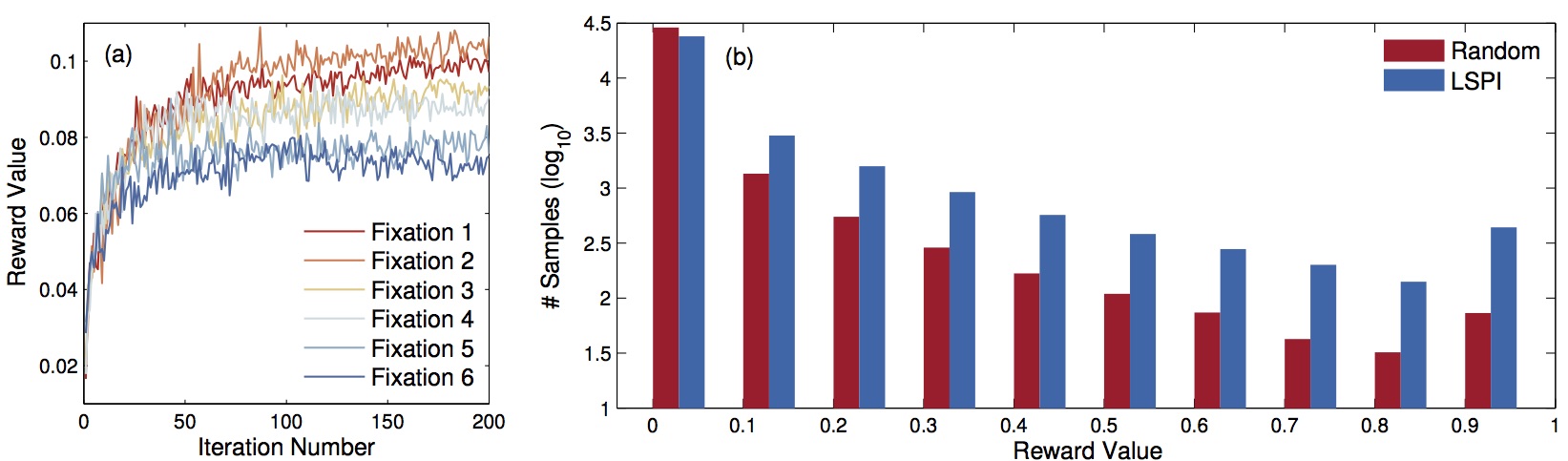 |
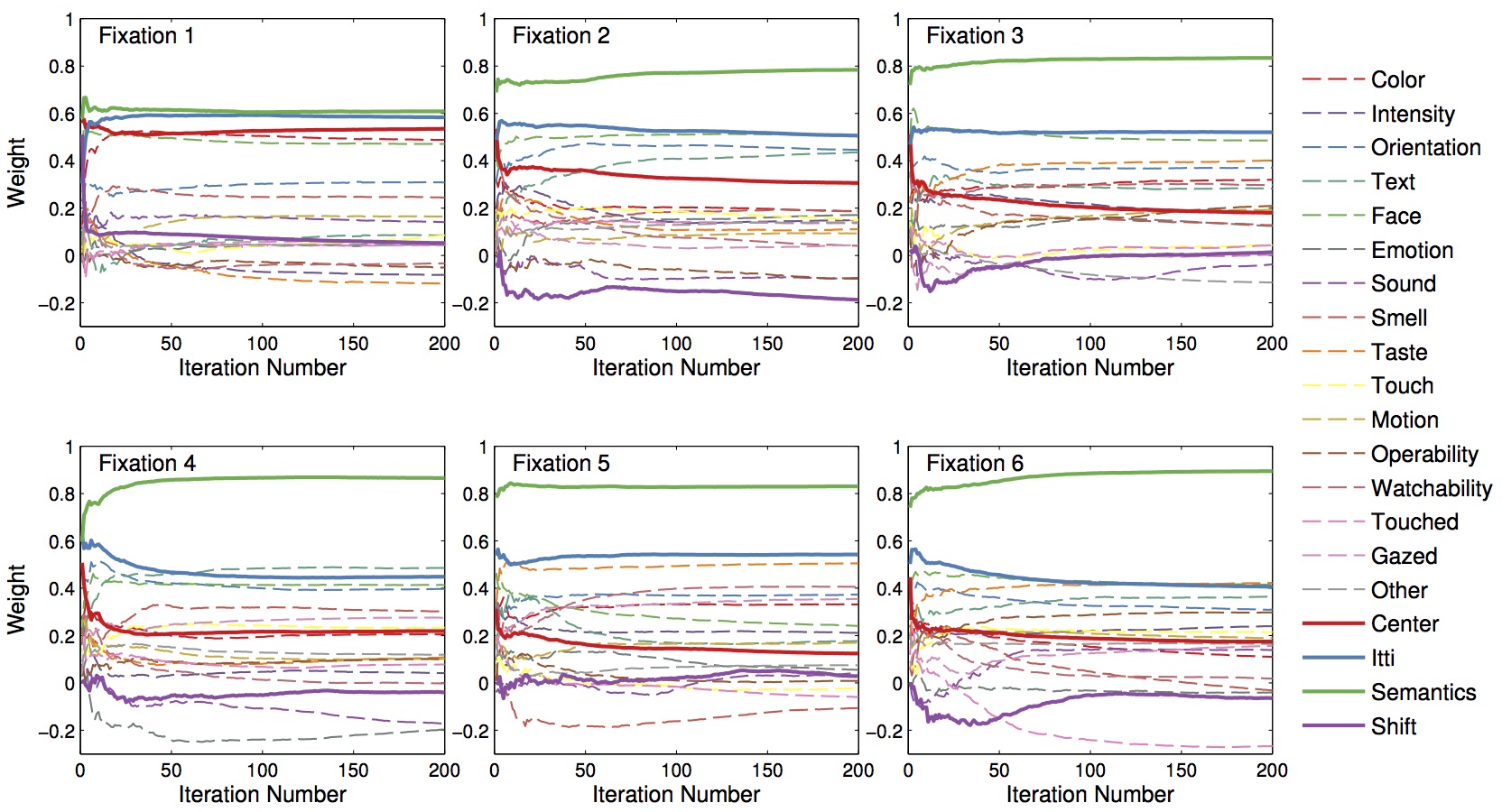 |
| Performance | |
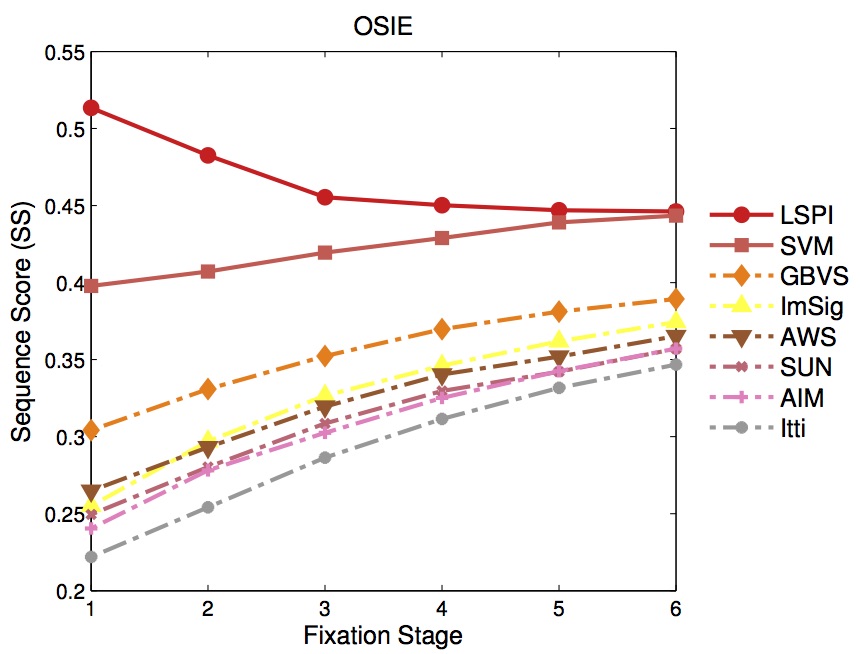 |
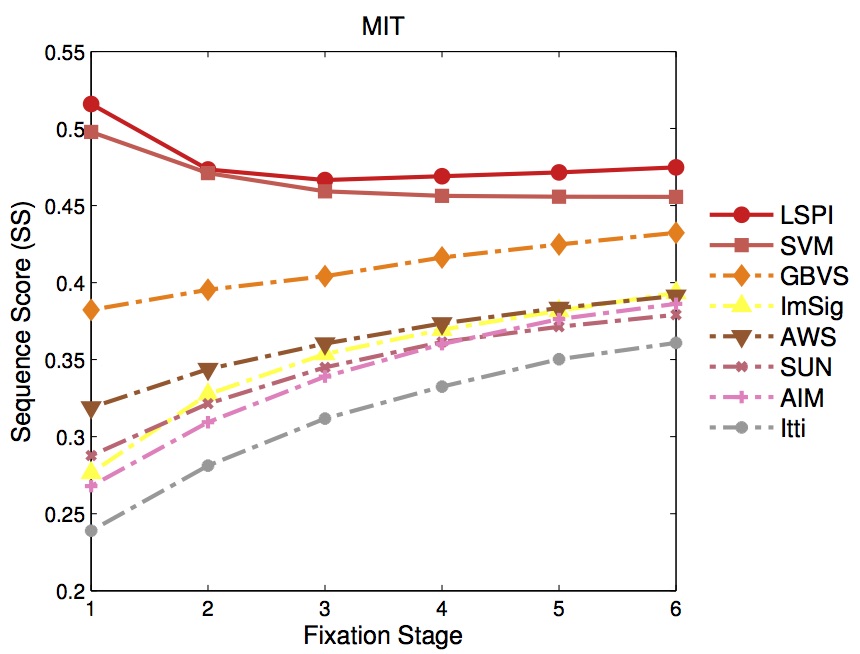 |
| Qualitative Comparisons |
|
|

