Predicting Human Scanpaths in Visual Question Answering
Xianyu Chen, Ming Jiang, Qi Zhao
University of Minnesota
Abstract
Attention has been an important mechanism for both humans and computer vision systems. While state-of-the-art models to predict attention focus on estimating a static probabilistic saliency map with free-viewing behavior, real-life scenarios are filled with tasks of varying types and complexities, and visual exploration is a temporal process that contributes to task performance. To bridge the gap, we conduct a first study to understand and predict the temporal sequences of eye fixations (a.k.a. scanpaths) during performing general tasks, and examine how scanpaths affect task performance. We present a new deep reinforcement learning method to predict scanpaths leading to different performances in visual question answering. Conditioned on a task guidance map, the proposed model learns question-specific attention patterns to generate scanpaths. It addresses the exposure bias in scanpath prediction with self-critical sequence training and designs a Consistency-Divergence loss to generate distinguishable scanpaths between correct and incorrect answers. The proposed model not only accurately predicts the spatio-temporal patterns of human behavior in visual question answering, such as fixation position, duration, and order, but also generalizes to free-viewing and visual search tasks, achieving human-level performance in all tasks and significantly outperforming the state of the art.

Visual scanpaths of humans can reveal their decision making strategies and explain their performance. Those who pay attention to relevant visual cues can achieve high levels of task performance. This example compares the scanpaths of people who succeed or fail to answer a question, where the dots represent fixations. The number and radius indicate the fixation order and duration, respectively. The blue and red dots indicate the beginning and the end of the scanpath, respectively.
Method
we propose a novel deep reinforcement learning method leveraging task guidance as an important modality to predict the visual exploration behavior of humans performing general tasks. We first introduce a task guidance map to specify task-relevant image regions. The map is designed and demonstrated to generalize across tasks. To address the exposure bias that arises between training- and test-time contexts, we introduce a reinforcement learning method that directly optimizes nondifferentiable test-time evaluation metrics. To differentiate eye-movement patterns that lead to different performances, we further introduce a novel loss function to account for the consistency and divergence between correct and incorrect scanpaths.
Our work has three distinctions from previous scanpath prediction studies:
- While state-of-the-art scanpath prediction studies focus on free-viewing or wellstructured tasks such as visual search, this paper for the first time studies the complex scanpath patterns in general decision-making tasks, and investigates the correlation of scanpaths and performances in this context.
- Scanpath prediction has not been as popular (compared with saliency prediction) or achieved excellent performance (compared with humans), partly due to the exposure bias - the discrepancy between training-time and test-time contexts. Here we close the gap using self-critical sequence training in the reinforcement learning method, leading to significantly boosted performance that is better than humans.
- We go beyond a single task and design a new mechanism to encode general task-relevant information that is easily adaptable to other tasks with varying nature and levels of complexity. The proposed method has been demonstrated by three tasks with human-level performance: VQA, free-viewing, and visual search.
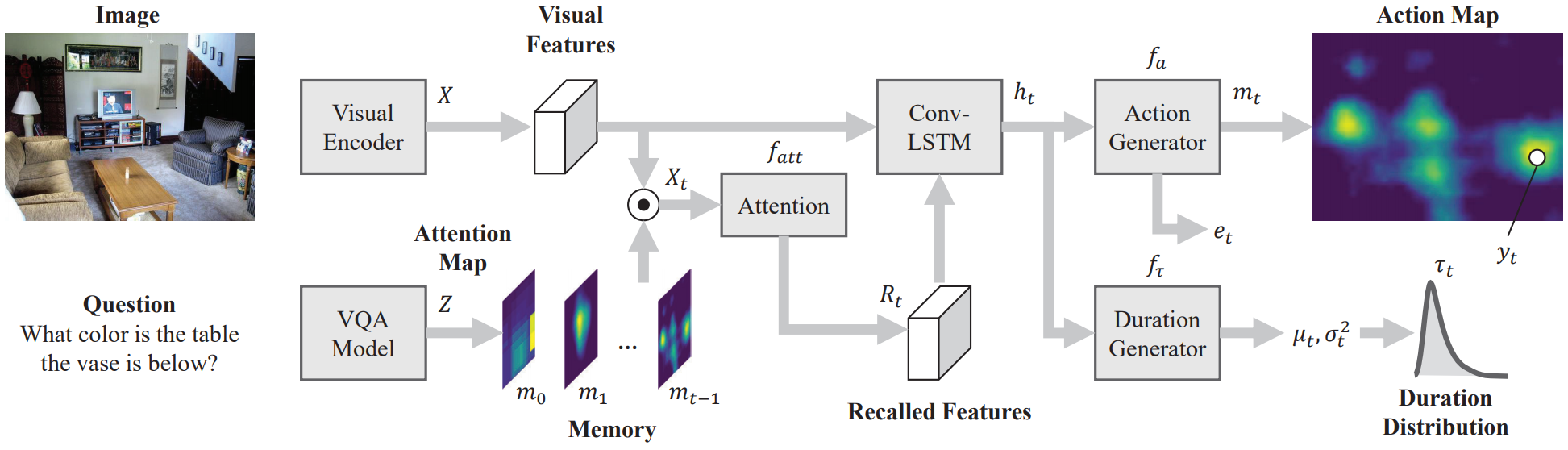
Overview of the proposed scanpath prediction network.
Results
We demonstrate our method with experiments on the GQA and VQAv2 datasets. Our method outperforms the state-of-the-art explicit reasoning methods, suggesting its superior ability to generate neural modules to explicitly reason over the enriched scene graph. Qualitative examples show that the complex reasoning process can be completely traced across multiple graph nodes:
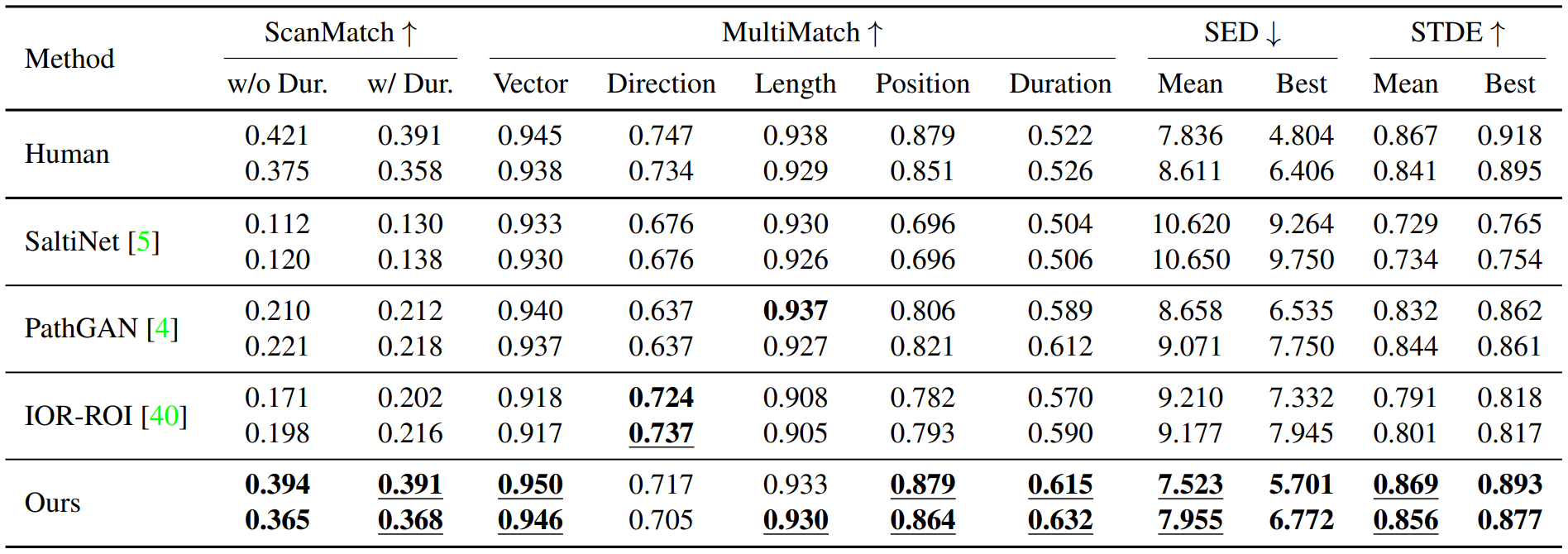
VQA. Scanpath prediction results on the AiR dataset (VQA). In each panel, the first row indicates the correct scanpaths and the second row indicates the incorrect scanpaths. The best results are highlighted in bold. Underlines indicate scores above human performance.
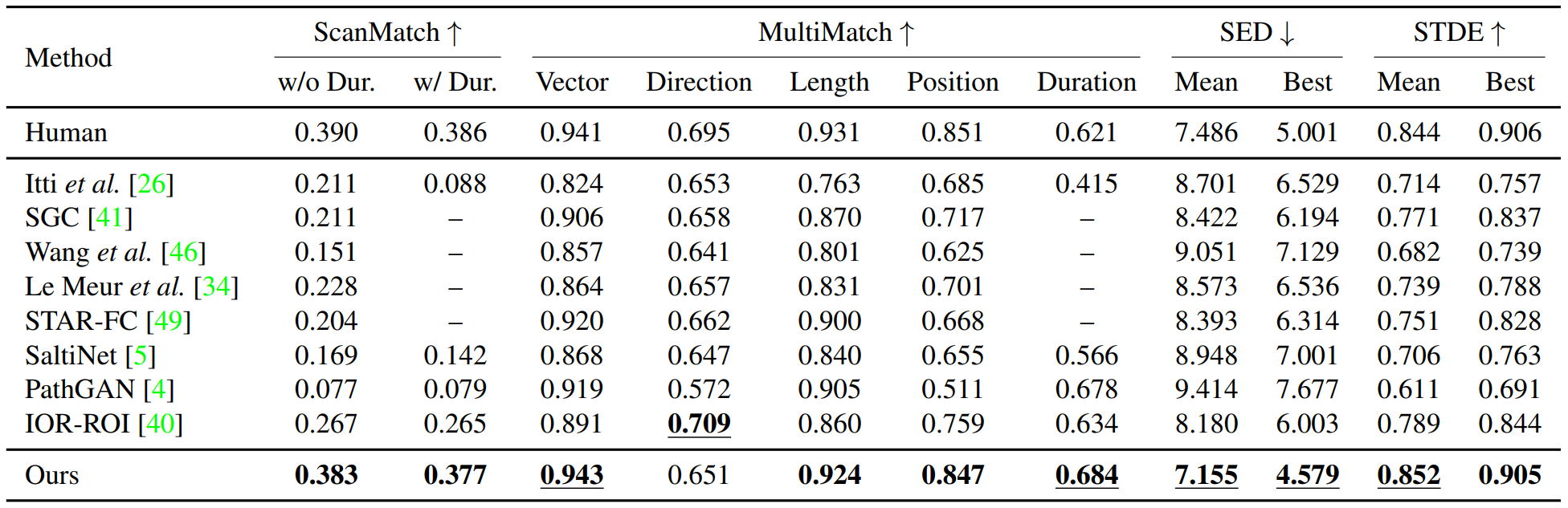
Free-Viewing. Performances on the OSIE dataset. The best results are highlighted in bold. Underlines indicate scores above human performance.
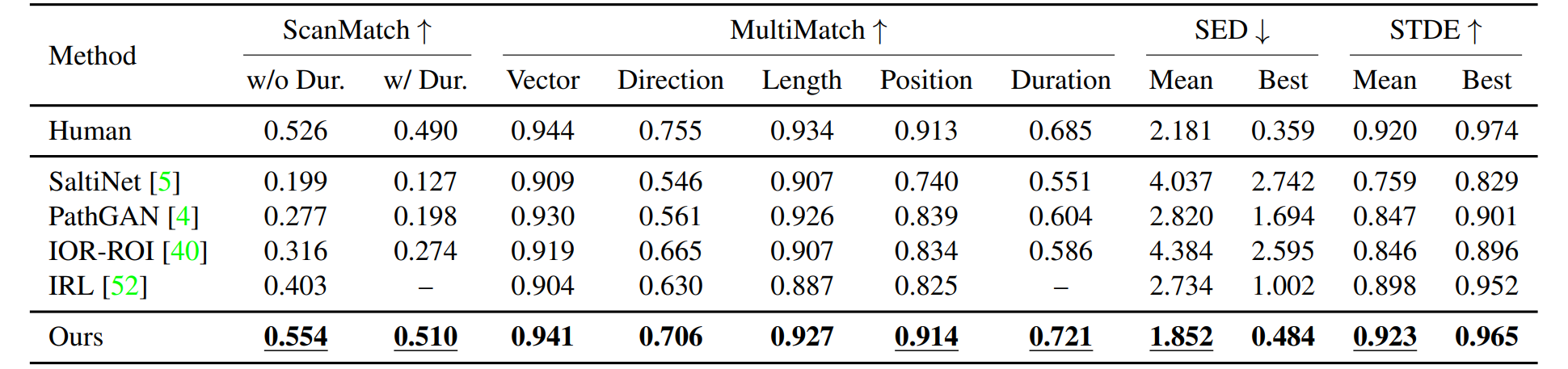
Visual Search. Performances on the COCO-Search18 dataset. The best results are highlighted in bold. Underlines indicate scores above human performance.
Download Links
Please cite the following paper if you use our dataset or code:
@InProceedings{Chen_2021_CVPR,
author = {Chen, Xianyu and Jiang, Ming and Zhao, Qi},
title = {Predicting Human Scanpaths in Visual Question Answering},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2021},
pages = {10876-10885}
}Acknowledgment
This work is supported by National Science Foundation grants 1908711 and 1849107.