Abstract
Visual attention is the ability to select visual stimuli that are most behaviorally relevant among the many others. It allows us to allocate our limited processing resources to the most informative part of the visual scene. In this work, we learn general high-level concepts with the aid of selective attention in a multi-layer deep network. Greedy layer-wise training is applied to learn mid- and high- level features from salient regions of images. The network is demonstrated to be able to successfully learn meaningful high-level concepts such as faces and texts in the third-layer and mid-level features like junctions, textures, and parallelism in the second-layer. Unlike object detectors that are recently included in saliency models to predict semantic saliency, the higher-level features we learned are general base features that are not restricted to one or few object categories. A saliency model built upon the learned features demonstrates its competitive power in object/social saliency prediction compared with existing methods.
Resources
Paper:
Chengyao Shen, and Qi Zhao, "Learning to Predict Eye Fixations for Semantic Contents Using Multi-layer Sparse Network," in Neurocomputing (Invited, Special Issue on Brain inspired models of cognitive memory), in press. [pdf] [bib]
Chengyao Shen, Mingli Song and Qi Zhao, "Learning High-Level Concepts by Training a Deep Network on Eye Fixations," in Deep Learning and Unsupervised Feature Learning Workshop, in conjunction with NIPS, Lake Tahoe, USA, December 2012. [pdf] [bib]
Code: Model with Training Data
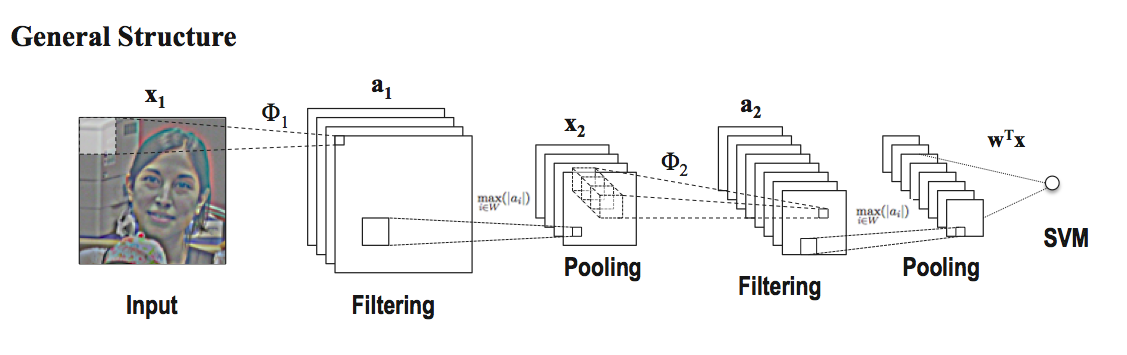
The Model
 |
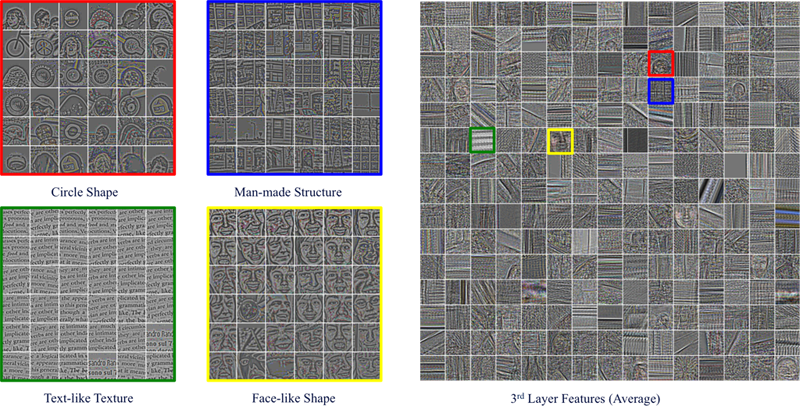
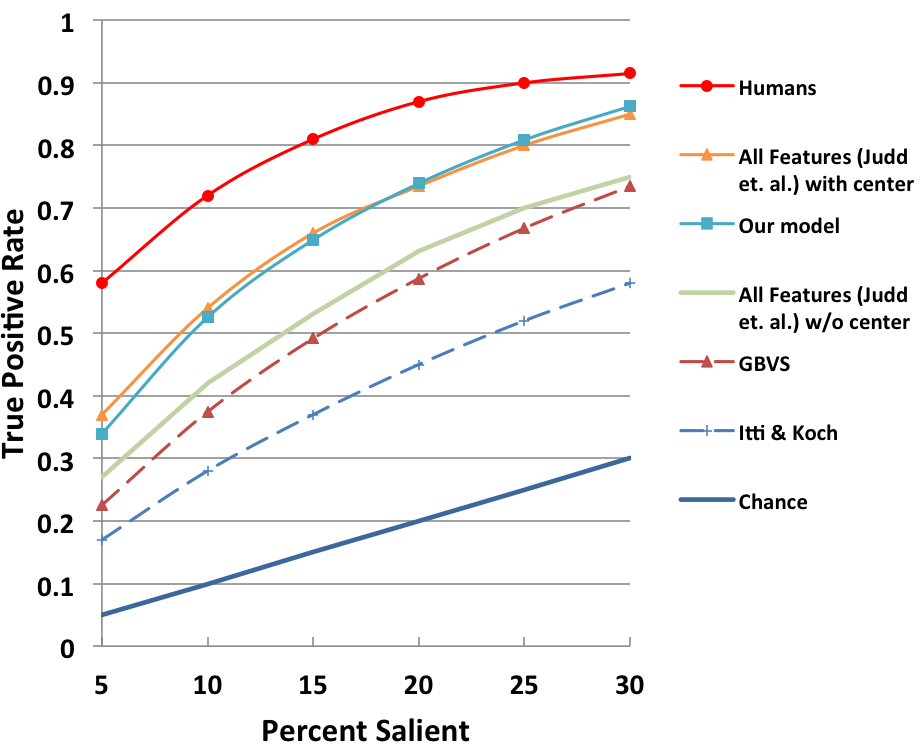
Results on MIT Fixation Dataset
| Visualization | |||
 |
|||
 |
|||
| Saliency Prediction |
|

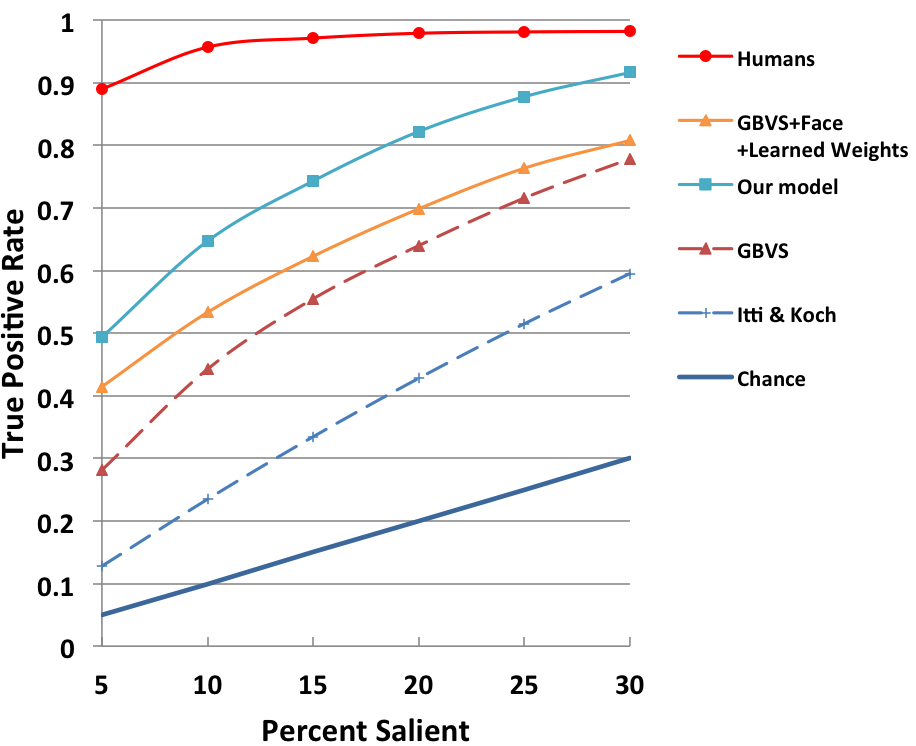
Results on FIFA Dataset
| Visualization | |
 |
|
| Saliency Prediction |
|