Abstract
One prominent feature of our visual system is that the fovea -- the highest-resolution portion of the retina -- only occupies two visual degrees, while the remaining portion of the retina (parafovea and periphery) are mainly in low-resolution. Therefore, before we make a saccadic eye movement, the potential fixation target is usually located in parafovea or periphery and is perceived in low-resolution. In this work, we present a computational framework based on convolutional neural network (CNN) to model this selective visual attention mechanism. By training the network with low-resolution inputs on potential fixation targets and non-salient locations, we find that proto-object representations emerge as a natural outcome for saliency prediction. These proto-object representations, which usually encode object gists and high-order statistics of a local region, demonstrate outstanding performance in predicting real eye fixation locations over other state-of-the-art saliency models. The component analysis also provides good insight into the validity of our approaches in improving the performance of the model.
Resources
Chengyao Shen, Xun Huang and Qi Zhao, "Emergence of Proto-Object Representations via Fixations in Low-Resolution", IEEE Transactions on Pattern Analysis and Machine Intelligence, under review. [pdf]
Chengyao Shen, Xun Huang and Qi Zhao, "Attention in Low Resolution: Learning Proto-Object Representations with A Deep Network", Vision Sciences Society (VSS) Annual Meeting, St. Pete Beach, Florida, 2015. [poster]
Motivations
Visual acuity of retina drops rapidly from central vision to peripheral vision. The fovea, which is the highest-resolution portion of the retina, only occupies two visual degree in the visual field, while the remaining portion of the retina (parafovea and periphery) are mainly in low-resolution. According to the relative visual acuity in human eye, the highest visual acuity of retina drops by a factor of two at 2.5 visual degree and five at 10 visual degree. Hence, at one specific moment, our visual perception of a natural scene would only have high visual acuity in the center of the gaze while the remaining parts are sampled in low visual acuity (as illustrated in the Figure below). To remedy this information degeneration in input, our brain employs a strategy of selective visual attention to build up our visual perception. In our daily life, our eyes could efficiently select potential fixation targets and constantly make saccadic eye movements to construct a continuous high-resolution perception of our visual environment.

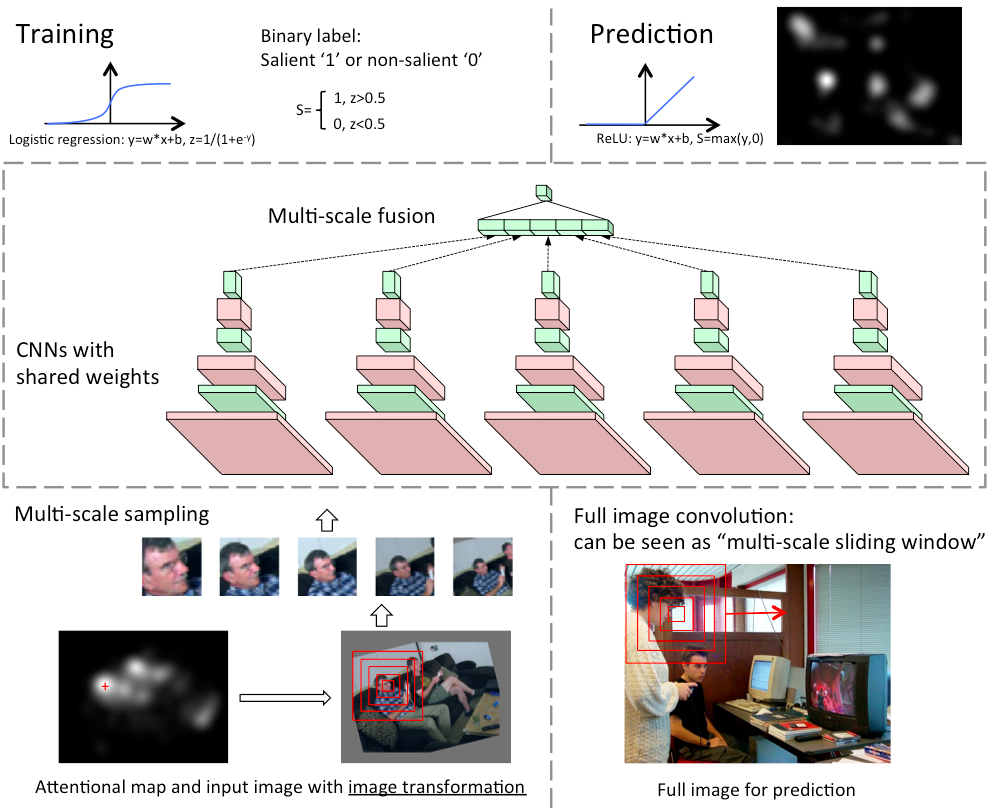
Network Structure
The network structure of a 3-layer model is shown below. Red blocks indicate the responses of convolution followed by a rectified linear unit, green blocks indicate the responses of pooling. In the training stage, multi-scale salient and non-salient patches are input into the network and the network is trained as a binary classification with logistic regression. In saliency prediction stage, a full image is fed into the network and a saliency map is generated with trained parameters:
Qualitative Results

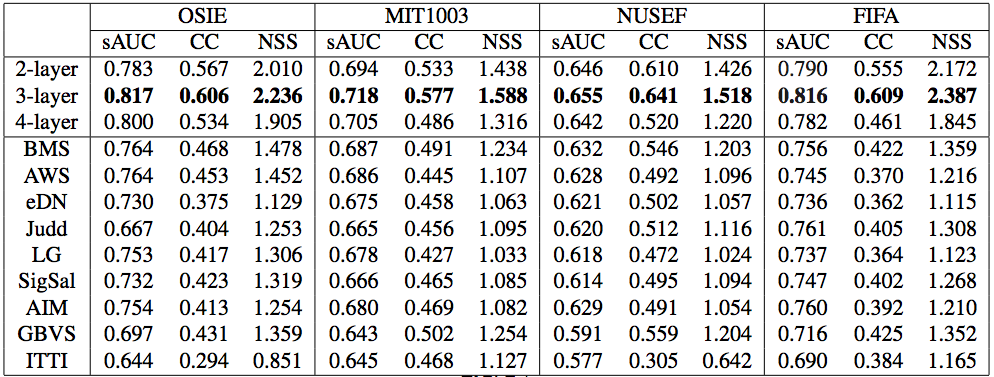
Quantitative Results
Visualizations of Learned Features
Visualization of layer 1 features by their weights:

Visualization of layer 2 features by calculating the mean of 64 top responsive input patches in their effective receptive field:

Visualization of layer 3 features by calculating the mean of 64 top responsive input patches in their effective receptive field:

Visualization of features in layer 3 with top 36 positive weights and expanded illustration of 4 typical features for potential fixation targets:

Visualization of features in layer 3 with top 36 negative weights and expanded illustration of 4 typical features for non-targets:
