Learning and Optimization
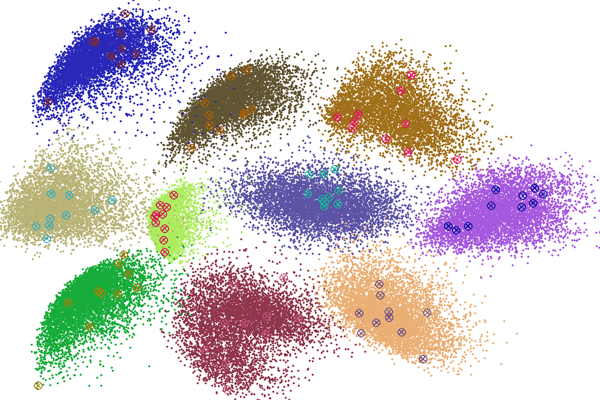 |
We work broadly on machine learning and optimization, with an recent emphesis in efficient and effective methods for big data analytics. Topics include: |
| Webpage: | Flexible Clustered Multi-task Learning by Learning Representative Tasks Safe Subspace Screening for Nuclear Norm Regularized Least Squares Problems |
Predicting Saliency Beyond Pixels
 |
A large body of previous attention models focus on pixel-level image attributes, while object- and semantic-level information is frequently ignored or deemphasized. Contributions in this work include (a) a new saliency architecture with multiple layers, (b) a principled vocabulary of attributes to describe object- and semantic-level cues, (c) a new dataset (OSIE) of 700 images with eye tracking data of 15 viewers and annotation of 5551 segmented objects and 12 semantic attributes, and (d) models to predict where humans look at beyond pixels. The dataset has been used in a number of ongoing neuroscience studies due to its rich semantics, for example, in autism eye tracking to study their altered saliency representation, in fMRI experiments to explore brain regions/networks underlying selective attention, and in single-unit experiments to study attention and memory. |
| Webpage: | Predicting Saliency Beyond Pixels |
Saliency in Crowd
Theories and models on saliency focus on regular-density scenes. A crowded scene is characterized by the cooccurrence of a relatively large number of regions/objects that would have stood out if in a regular scene, and what drives attention in crowd can be significantly different from the conclusions in the regular setting. To facilitate saliency in crowd study, a new dataset (EyeCrowd) of 500 images is constructed with eye tracking data from 16 viewers and annotation data on faces. Statistical analyses point to key observations on features and mechanisms of saliency in scenes with different crowd levels. Backed on the data and observations, a new computational model taking into account the crowding information is proposed to predict important regions in a scene. |
|
| Webpage: | Saliency in Crowd |
Webpage Saliency
Webpages have become an increasingly important source of information for a large population in the world. Understanding what attracts attention in viewing a webpage has both scientific and commercial values. For example, webpage design is of interest to both Internet users as well as to online marketers and advertisers. While there are few studies on saliency in webpage, we build a Fixation in Webpage Images (FiWI) dataset with 149 webpage images and eye tracking data from 11 subjects who free-viewed the webpages. Insights of the viewing patterns and computational models to predict where to look at while viewing webpages are reported. In a follow-up work, multi-scale features are also learned from deep networks and used for saliency prediction in webpages. |
|
| Webpage: | Webpage Saliency |
Multi-Camera Saliency
A significant body of literature on saliency modeling predicts where humans look in a single image or video. Besides the scientific goal of understanding how information is fused from multiple visual sources to identify regions of interest in a holistic manner, there are tremendous engineering applications of multi-camera saliency due to the widespread of cameras. This work proposes a principled framework to smoothly integrate visual information from multiple views to a global scene map, and to employ a saliency algorithm incorporating high-level features to identify the most important regions by fusing visual information. |
|
| Webpage: | Multi-Camera Saliency |
Scanpath Prediction
Unlike most state-of-the-art attention models that estimate the probability distribution of fixating the eyes in a location of the image (the saliency maps), this work explores the temporal dimension and learns to predict sequences of human fixations. With the extra dimension, the study aims to better predicting fixations, as well understanding the role of the different cues that drive fixations and fixation shifts. Least-Squares Policy Iteration is used to learn a visual exploration policy that mimics the recorded eye-fixation examples. Experiments demonstrate the effectiveness of the method for combining multiple cues at different stages of the scanpath. The learned parameters suggest that the low-level and high-level cues (semantics) are similarly important at the first eye fixation of the scan-path, and the contribution of high-level cues keeps increasing during the visual exploration. |
|
| Webpage: | Learning to Predict Sequences of Human Fixations |
Visual Search
|
People with ASD have pervasive impairments in social interactions, a diagnostic component that may have its roots in atypical social motivation and attention. One of the brain structures implicated in the social abnormalities seen in ASD is the amygdala. To further characterize the impairment of people with ASD in social attention, and to explore the possible role of the amygdala, we employed a series of visual search tasks with both social (faces and people with different postures, emotions, and ages) and non-social stimuli (e.g., electronics, food, utensils). Our findings show an attentional deficit in ASD that is disproportionate for social stimuli, cannot be explained by low-level visual properties of the stimuli, and is more severe with high-load top-down task demands. Furthermore, this deficit appears to be independent of the amygdala, and not evident from general social bias independent of the target-directed search. |
|
| Webpage: | People with Autism but not People with Amygdala Lesions are Impaired to Look at Target Relevant Social Objects in Visual Search |
Mind Reading with Eye Tracking
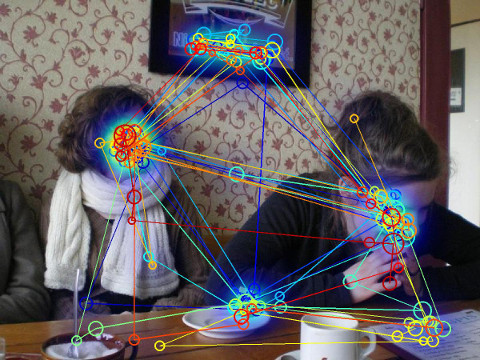 |
Despite the popularity and convenience of eye tracking experiments, a well-known and long-lasting problem in the conventional paradigms is their limited power in reading the internal mental status. For example, a subject can be totally unaware of the contents even though fixations were recorded on top of the region - most studies simply assumed that what is "fixated" is what is "seen", which is not always true. This research aims to read mind with eye tracking data. |
| Webpage: | Predicting Mental Status in Visual Search using Eye Fixation Metrics |
Visual Tracking
|
For both the natural visual system as well as the artificial ones, visual input is continuous. To utilize temporal correlation and enforce temporal coherence, we develop visual trackers to keep track of the objects/regions of interest. One challenge in visual tracking is that object appearance can change drastically over time due to for example illumination changes, pose changes, view changes, etc. Our methods use biologically inspired mechanisms to approach the invariance problem and achieve reasonable results. |
|
| Webpage: | Differential Earth Mover's Distance Matching |
Action Recognition
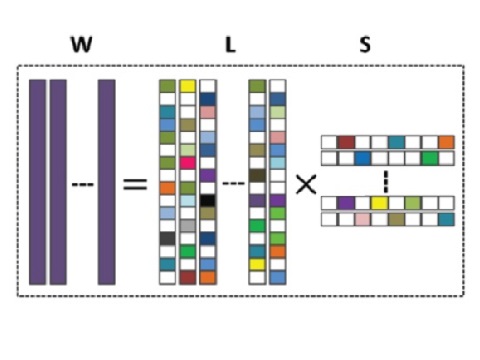 |
Many action categories are related, in a way that common motion patterns are shared among them. For example, diving and high jump share the jump motion. To explore and model such relation, we in a series of works investigate knowledge sharing across categories for action recognition in videos. The proposed learning method is also applicable to other problems where information sharing exists in a similar manner. |
| Webpage: | Learning to Share Latent Tasks for Action Recognition |
Augmented Reality - Subtle Cueing
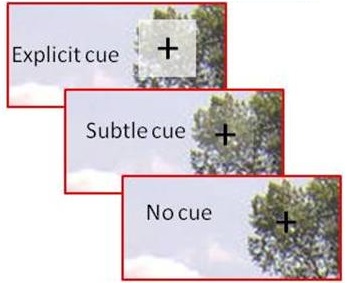 |
Traditionally, Augmented Reality (AR) visualizations have been designed based on intuition, leading to many ineffective designs. For more effective AR interfaces to be designed, user-based experimentation must be performed, which is lacking in the AR community. We here develop a set of empirical experiment methods and an apparatus for use in AR environments, in the hope that this work will guide future researchers in performing such experiments. To evaluate the contributions, the work has been applied in experiments which addressed a classical problem in AR caused by the use of explicit cues for visual cueing in Visual Search tasks, in which these explicit cues may occlude and clutter the scene, leading to scene distortion. In particular, we use Subtle Cueing, a method of directing visual attention that does not distort, clutter or occlude the scene. A Virtual Reality simulator is constructed to investigate the properties and attributes of Subtle Cueing. Using this simulator, we are able to show that despite the subtlety of the subtle cue, it still had a significant cueing effect. |
| Webpage: | Subtle Cueing in Augmented Reality Environments |